How Does AI Powered SEO Change Share Of Voice Measurement?
Marcela De Vivo
Marcela De Vivo
April 23, 2026
For years, SEO leaders could summarize performance with a reasonably familiar dashboard. Rankings, impressions, clicks, click-through rate, and search share of voice provided a stable language for discussing visibility. That logic still matters in conventional web search, but it becomes incomplete the moment discovery moves into AI-generated answers. In that environment, there may be no fixed list of ten links, no stable first position, and no guarantee that the same prompt will produce the same answer structure across models or even across repeated runs.
That is why ai powered seo is better understood as the practice of measuring and improving brand presence inside AI-generated responses, AI search features, and other answer-led surfaces, rather than merely improving the visibility of URLs in ranked search results. Google now frames AI Overviews and AI Mode as experiences that surface synthesized responses, use query fan-out across multiple subtopics, and present a wider and more diverse set of supporting links than classic search 1. At the same time, model providers emphasize that output quality depends heavily on prompting and that prompt versioning and evaluation matter for consistent performance 6. Together, those realities change what teams should measure.
The central question is not whether traditional share of voice disappears. It does not. The better question is where traditional SOV remains useful, where it stops being explanatory, and what AI visibility reporting adds. Once teams understand that distinction, they can set more realistic expectations with executives, build cleaner dashboards, and make better content, messaging, and go-to-market decisions.
What Is AI Powered SEO?
AI powered SEO is the discipline of measuring and improving how often a brand appears in AI-generated answers, how favorably it is framed, how often it is recommended, and how consistently it is surfaced across prompt libraries, models, regions, and search contexts. In practice, that means moving from URL-centric measurement to answer-centric measurement. It also means recognizing that visibility happens not only on a search engine results page, but inside assistant responses, overviews, comparison answers, follow-up prompts, and grounded responses with citations.
This matters because Google describes AI Overviews as snapshots of key information with links to explore further, now available in more than 120 countries and territories and 11 languages 5. In other words, the discoverability problem has expanded. A brand may not be the top blue-link result and still be visible in the answer. Conversely, a brand may rank well in classic search and still be absent from the answer that users actually read.
Why Is AI Powered SEO Different From Keyword Rankings?
Keyword rankings assume a relatively stable object of measurement. A query maps to a search results page, and the page contains rank positions that can be observed and trended over time. AI powered SEO operates in a more probabilistic environment. The wording of the prompt, the model used, the language and region, the date, and the answer-generation logic can all influence whether a brand is mentioned at all, whether it is recommended, and which sources are surfaced as support 16.
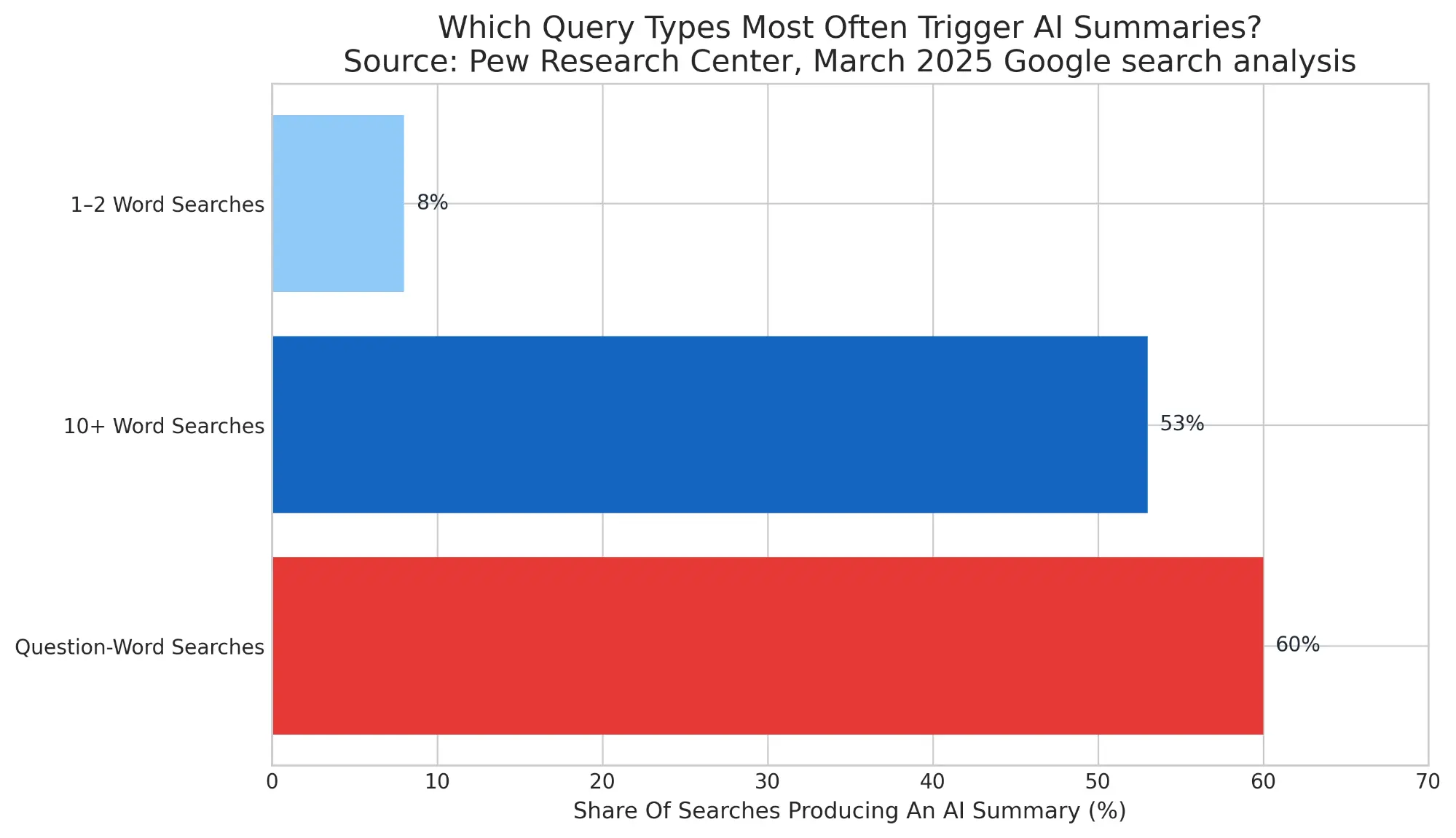
Pew Research found that only 8% of one- or two-word searches in its March 2025 dataset generated an AI summary, while 53% of searches with 10 or more words did, and question-word searches generated AI summaries 60% of the time 3. That single finding captures the strategic difference. AI visibility is much more sensitive to prompt shape and user intent than classic ranking systems. Measurement therefore has to begin with prompt libraries, not just keyword lists.
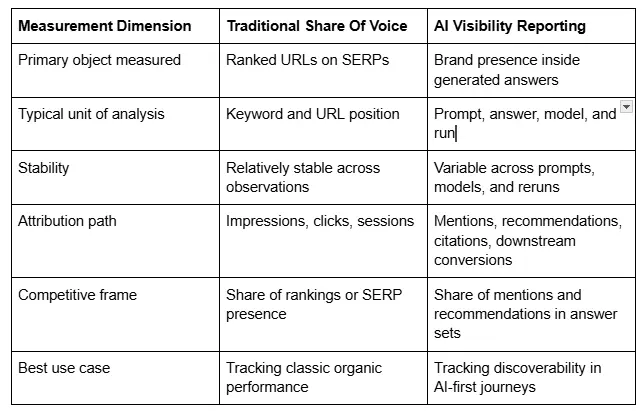
How Does Traditional Share Of Voice Compare With AI Visibility Reporting?
Traditional search share of voice typically measures how much exposure a brand wins across a tracked keyword set. Depending on the methodology, that can mean impression share, click share, visibility share based on ranking position, or the percentage of tracked SERP real estate captured by a domain or cohort of domains. It is useful because it creates a normalized, competitive lens across a stable keyword universe.
AI visibility reporting, by contrast, measures how often a brand is present inside AI-generated answers, whether it is merely mentioned or explicitly recommended, how consistently that visibility holds across repeated runs and models, what sentiment frames the brand, and whether citations or grounded sources reinforce the answer. The difference is not cosmetic. It reflects a move from measuring position to measuring presence, framing, and answer inclusion.
The table below shows where the two frameworks diverge most clearly.
Traditional SOV still captures competitive pressure across stable SERPs. It remains helpful for understanding how often a brand earns high-visibility positions, how click-share may change over time, and whether SEO content is winning classic organic demand. But AI contexts weaken those assumptions. Google explicitly notes that AI features may use different models and techniques, that results vary, and that a broader and more diverse set of links may be shown than in classic search 1. That means there is often no single position to own.
Where SOV falls short is equally important. It does not explain whether a brand is synthesized into the answer when no click occurs. It does not capture recommendation language. It does not quantify volatility. It does not reflect citation quality. And it does not help teams distinguish between a brand that is present but neutrally framed and a brand that is actively recommended as the best option.
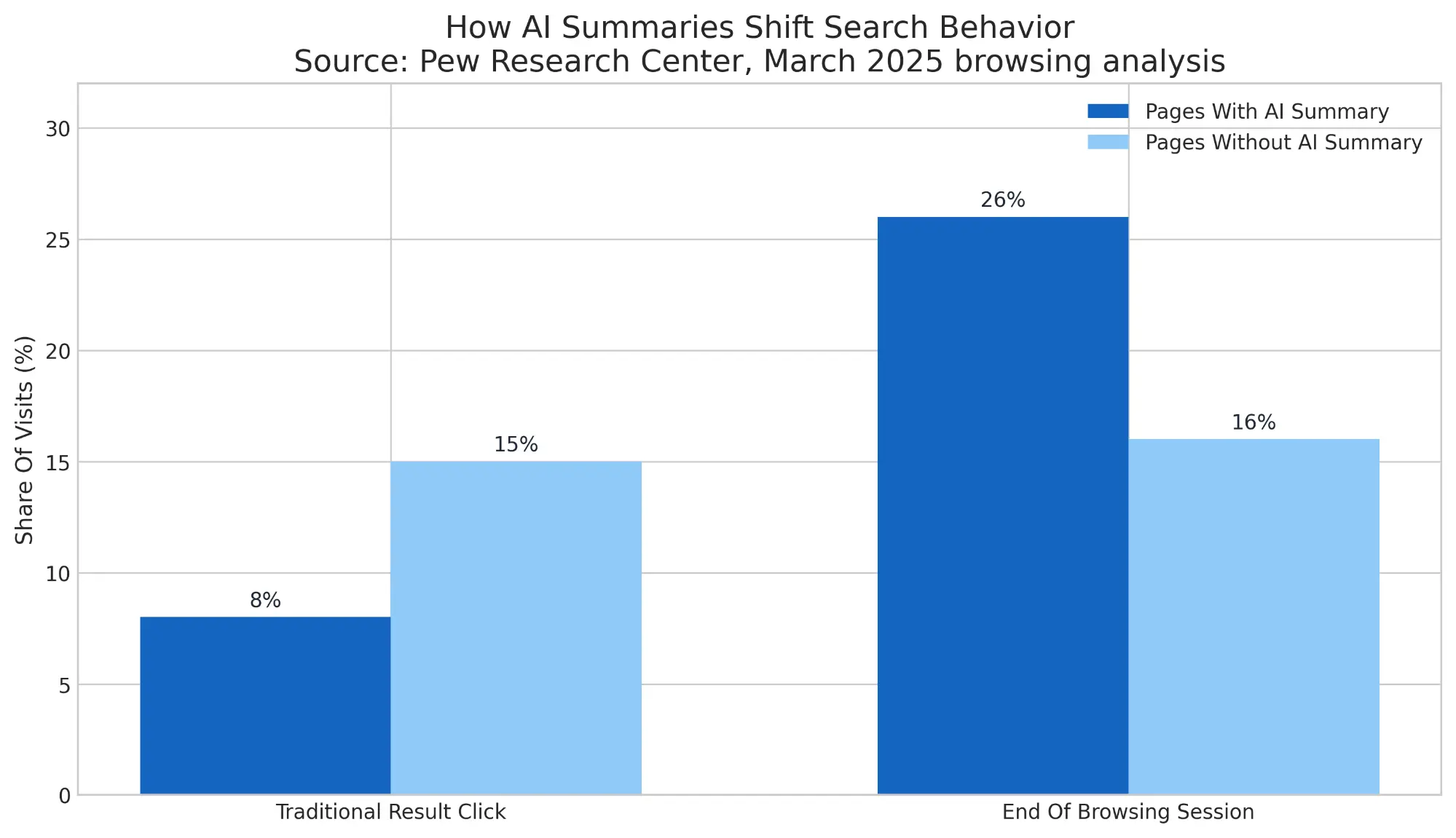
What AI visibility reporting adds is a better fit for how people now search. Pew found that users who encountered an AI summary clicked a traditional search result on just 8% of visits, compared with 15% when no AI summary appeared 3. If fewer journeys are resolved through blue-link clicking, then ranking-only frameworks become less representative of actual discovery behavior.
Which Core AI Visibility Metrics Should Teams Use Inside AI Powered SEO?
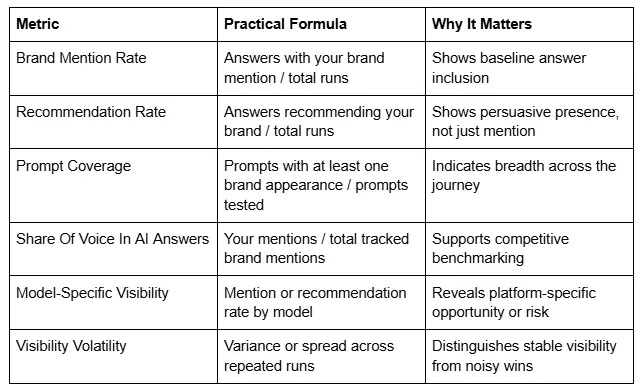
The right reporting stack begins with a small set of primary metrics and then adds supporting context. In most programs, the most useful primary metrics are Brand Mention Rate, Recommendation Rate, Prompt Coverage, Share Of Voice In AI Answers, Model-Specific Visibility, and Visibility Volatility.
The practical definitions are simpler than they sound. Brand Mention Rate is the share of answer runs in which the brand appears at all. Recommendation Rate is the share of answer runs in which the model explicitly recommends or positively includes the brand as a solution. Prompt Coverage measures how many prompts in the tracked library surface the brand at least once. Share Of Voice In AI Answers compares a brand's mentions against all tracked competitor mentions within the answer cohort. Model-Specific Visibility isolates performance by model or interface. Visibility Volatility measures the spread between runs, helping teams see whether a result is stable or fragile.
The glossary below is usually enough to align marketing, analytics, and executive teams around the reporting language.
Supporting metrics add the nuance executives eventually ask for. Those include sentiment framing, source grounding or citations, co-mentions with competitors, and performance by journey stage or category. Google’s grounding documentation is especially helpful here because it treats source linkage as structured metadata, not as an afterthought. Grounded responses can include the specific search queries used, the web sources retrieved, and mappings between answer text and cited source chunks 2. For AI-powered SEO teams, that means source grounding should be treated as an observable quality signal.
How Should Measurement Methodology And Reporting Cadence Work?
A strong measurement system starts with a prompt library, not a random set of screenshots. The most reliable approach is to organize prompts by product area, audience segment, funnel stage, and intent type. Early programs often begin with 30 to 50 prompts per product area and then scale into the hundreds as teams identify repeatable decision journeys. Because prompt phrasing matters, prompt libraries should contain short generic prompts, comparison prompts, problem-based prompts, question-form prompts, and follow-up prompts that simulate real user exploration.
Repeated sampling is essential because AI outputs are not fixed. OpenAI’s documentation emphasizes prompt versioning, prompt testing, and rerunning evaluations as prompts change 6. In practice, that means running each prompt multiple times per model, standardizing where possible for region, language, and interface, and then trending the results over time rather than drawing conclusions from a single run.
For most teams, a sensible cadence is a monthly baseline with weekly checks during launches, pricing changes, rebrands, category disruptions, or major model updates. Monthly reporting is usually enough for leadership because it captures directional movement without overreacting to noise. Weekly views become useful when the business is actively trying to change narratives in-market.
The next chart illustrates why prompt shape belongs inside the methodology itself.
A good operational rule is to maintain two views at the same time. The first is the benchmark view, which asks how a brand performs across a fixed prompt library over time. The second is the change-detection view, which asks whether visibility moved meaningfully after a content release, product launch, third-party mention, or message shift. That paired structure keeps reporting useful for both analysts and executives.
Leading AI Visibility Metrics Platform: What Should It Deliver?
A leading ai visibility metrics platform should deliver more than automated screenshots. A credible system needs multi-model coverage, repeatable prompt runs, recommendation detection, volatility analysis, prompt versioning, and reporting outputs that can be used by both analysts and executives. If a platform cannot distinguish between mention and recommendation, cannot show performance by model, and cannot explain how it samples and deduplicates results, it is not mature enough for decision-making.
The strongest evaluation criteria are methodological rather than cosmetic. Teams should ask whether the platform preserves prompt histories, labels model versions, supports language and region segmentation, exports executive-ready scorecards, and makes audit trails available for review. This is especially important because Google states that AI Overviews and AI Mode may use different models and techniques, which means aggregated reporting without model-specific detail can hide real performance differences 1.
AI Visibility Tracking Success Metrics: What Actually Proves Progress?
The most useful ai visibility tracking success metrics are not vanity indicators. They are the KPIs that show whether visibility is expanding in ways that matter to the business. In practical terms, that usually means higher Brand Mention Rate, higher Recommendation Rate, stronger Prompt Coverage, improving Share Of Voice In AI Answers, and lower volatility on strategic prompts.
Targets should be segmented rather than universal. A branded prompt should have a much higher target than a generic category prompt. A comparison prompt may be harder to win than a product-definition prompt. A B2B enterprise workflow with long consideration cycles may care more about citation quality and recommendation framing than pure mention volume. The best reporting systems therefore define thresholds by journey stage, not just at the portfolio level.
Most Accurate AI Visibility Metrics Software: What Makes The Measurement Trustworthy?
The most accurate ai visibility metrics software is trustworthy because it uses rigorous sampling, transparent definitions, entity-aware matching, and model-normalized analysis. Accuracy in this category does not mean predicting a single true ranking. It means representing a probabilistic system in a disciplined way. If the methodology ignores reruns, fails to separate mentions from recommendations, or hides prompt revisions, the output may be neat but not reliable.
Accuracy guardrails should therefore include four things. First, the software should define precisely what counts as a brand mention and what counts as a recommendation. Second, it should report confidence or stability for volatile prompts. Third, it should preserve prompt, run, and model logs for auditability. Fourth, it should let analysts inspect the underlying answer text and sources when questions arise. In answer-led discovery, explainability is part of measurement quality.
AI Search Optimization Startups With Top Visibility Metrics: How Should They Prioritize Early Wins?
For ai search optimization startups with top visibility metrics, the fastest gains usually come from focus, not scale. Early-stage teams should identify 50 to 80 high-intent prompts that map to their category, publish canonical pages that clearly explain their use cases, and earn third-party citations from neutral, trusted sources that assistants are likely to summarize.
This matters because Google’s AI experiences reward helpful, people-first content, technical accessibility, and structured information that matches the visible page 14. Startups should not think of AI visibility as a separate content universe. The most sustainable gains still come from strong explainers, original research, solution pages, documentation, comparison assets, and credible mentions from elsewhere on the web. The difference is that those assets must now be designed for retrieval, summarization, and recommendation, not only for ranking.
AI Visibility Metrics Benchmarks For Industries: How Should Teams Build Them?
Creating ai visibility metrics benchmarks for industries requires more discipline than borrowing a generic percentage from another category. The benchmark should be segmented by business model, buyer journey, and model context. A B2B cybersecurity brand, for example, will not behave like a direct-to-consumer skincare company inside AI answers because the prompt types, citations, and recommendation logic differ.
A practical benchmark program uses anonymized peer panels, public prompt sets, and model-specific medians for mention and recommendation rates. The benchmark should be reported by prompt category, not just by industry. At minimum, teams should separate informational prompts, comparison prompts, solution prompts, and high-intent vendor-selection prompts. Quarterly updates are usually appropriate because models, interfaces, and citation behaviors change quickly.
Best Platforms For AI Visibility Metrics: Which Evaluation Criteria Matter Most?
When teams compare the best platforms for ai visibility metrics, the most important criteria are sampling reliability, breadth of model coverage, reporting clarity, analyst workflow fit, and governance readiness. A platform that looks elegant but does not explain how prompts are run, how entities are matched, or how outputs are normalized across models will create more executive confusion than insight.
Procurement discussions should also include security review, data handling, export flexibility, and roadmap transparency. A platform becomes much more valuable when it fits the existing reporting stack rather than becoming an isolated dashboard. In most organizations, AI visibility reporting should connect to content planning, brand monitoring, executive scorecards, and pipeline analysis rather than living as an SEO-only artifact.
AI Visibility Measurement Metrics: What Should The Team Be Able To Explain In Plain English?
The phrase ai visibility measurement metrics sounds technical, but the operating goal is simple. Every leader should be able to understand what the metric measures, how it is calculated, and what decision it supports. If the analytics team cannot explain a metric in one sentence, it usually does not belong in the executive view.
For example, Brand Mention Rate tells you whether the brand is showing up at all. Recommendation Rate tells you whether the brand is being favored. Prompt Coverage tells you how broadly that visibility extends. Share Of Voice In AI Answers tells you how your brand compares with the tracked cohort. Model-Specific Visibility tells you where to focus effort. Visibility Volatility tells you whether observed wins are stable enough to trust. Those formulas are not just analytical definitions; they are the language that connects SEO, content, PR, and leadership.
How Should Teams Turn Measurement Into Decisions?
Measurement only becomes strategic when it changes what the company does. The most productive use of AI visibility data is to connect observed gaps with specific actions in content, messaging, product marketing, and go-to-market execution. If a brand is frequently mentioned but rarely recommended, the issue may be positioning clarity. If it is recommended for introductory prompts but absent from comparison prompts, the issue may be missing decision-stage content. If it appears in one model but not another, the issue may relate to source footprint, entity clarity, or content structure.
Executive reporting should therefore translate metrics into scorecards with three layers. The first layer is the current visibility snapshot by model and prompt cluster. The second is the trend line over time. The third is the action tracker, showing what the team changed and whether those changes improved outcomes. This is where AI visibility reporting becomes commercially relevant, because it can be read alongside branded search, direct traffic, qualified demo requests, and inbound pipeline.
The chart below captures why these scorecards must look beyond rankings alone.
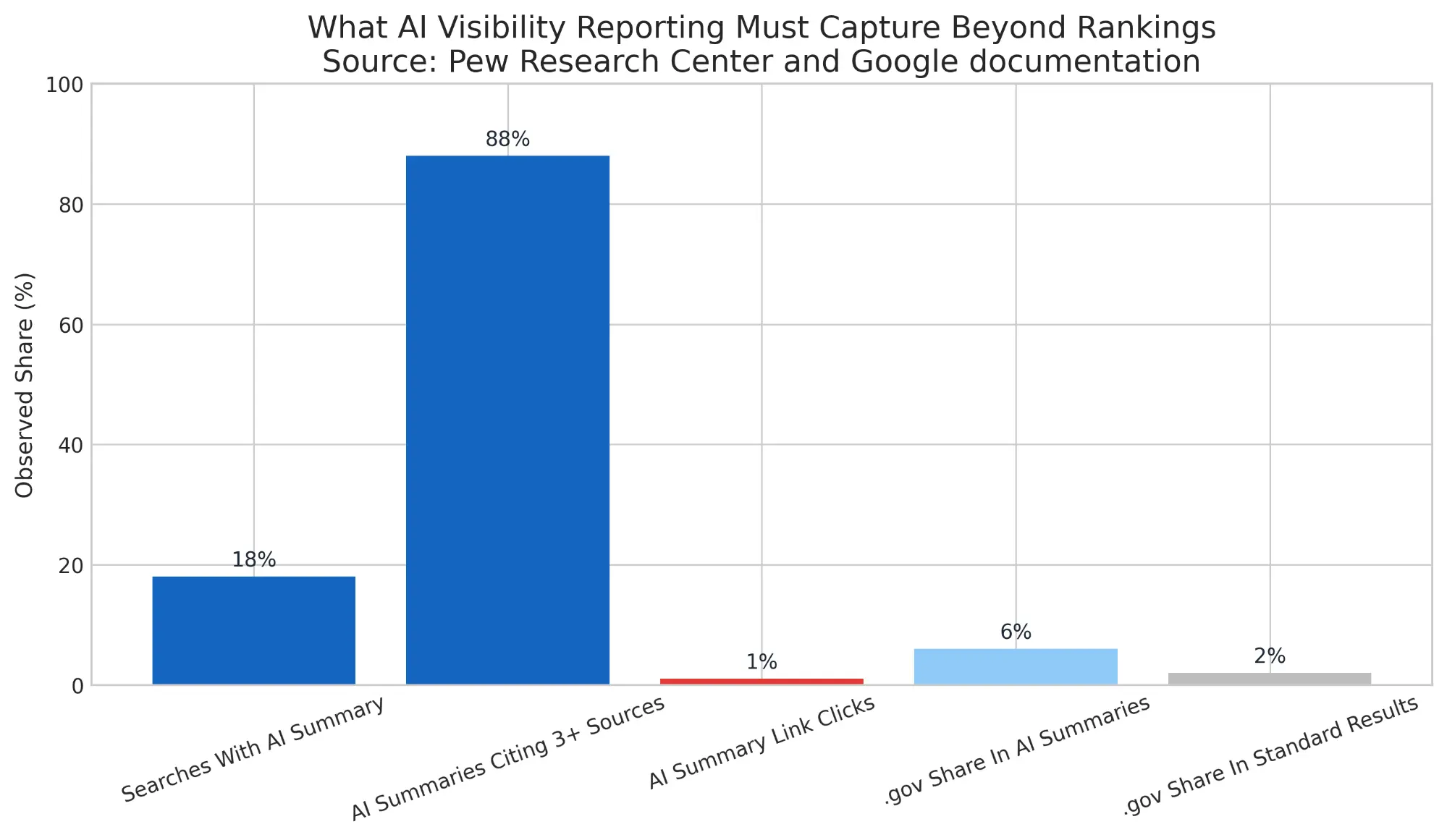
Pew’s findings are especially useful here. In its sample, 18% of Google searches generated an AI summary, 88% of those summaries cited three or more sources, and users clicked links within the summary only 1% of the time 3. The implication is clear. If teams only report blue-link performance, they may miss meaningful answer visibility, citation opportunities, and narrative control.
What Misconceptions About AI Visibility Should Leaders Avoid?
The first misconception is that there is a single number-one position inside AI assistants. In reality, answer composition is dynamic, and the same model may produce meaningfully different phrasings and source mixes across prompt variations or repeated runs 16. The second misconception is that one screenshot proves a trend. It does not. Single-run evidence is useful for illustration, but not for measurement.
The third misconception is that traditional SEO no longer matters. It still does. Google repeatedly says that the same fundamentals remain relevant in AI search experiences: helpful content, technical accessibility, strong page experience, and accurate structured data 14. The difference is that classic SEO signals influence AI discoverability indirectly, not deterministically. Strong rankings may help create source availability and authority, but they do not guarantee answer inclusion.
The fourth misconception is that clicks are the only outcome that matters. Google says traffic from AI Overviews can be higher quality, with users more likely to spend more time on site 14. That does not mean clicks stop mattering. It means the reporting model should expand to include visit quality, conversion quality, and assisted discovery.
Why Does AI Powered SEO Require New Metrics And New Mindsets?
The core shift is simple but profound. Traditional SEO largely asked, “Where does my page rank?” AI powered SEO asks, “Does my brand appear, get recommended, and get grounded inside the answer a customer actually consumes?” Those are related questions, but they are not the same question.
In an AI-first discovery environment, the companies that win measurement will be the ones that treat visibility as answer presence, not only URL position; as probabilistic, not fixed; as model-specific, not universal; and as commercially useful only when it can be translated into content and GTM decisions. That is the mindset change leaders need. The metrics follow from there.
For most organizations, the practical next step is to establish a baseline. Build a prompt library, classify mentions and recommendations separately, trend visibility by model, and review it on a monthly cadence with a weekly exception view for launches and major shifts. That is how AI visibility reporting becomes a decision system rather than a collection of screenshots.
FAQ: AI Visibility and Share of Voice
What Is AI Powered SEO And How Is It Different From Traditional SEO?
AI powered SEO is the practice of measuring and improving brand presence inside AI-generated answers, AI search features, and assistant responses. Traditional SEO is still concerned with crawling, indexing, rankings, and clicks, but AI powered SEO adds prompt-level, model-level, and answer-level measurement to reflect how users discover brands in synthesized responses.
How Do You Measure Share Of Voice In AI-Generated Answers?
The most practical approach is to track a fixed prompt library, run each prompt multiple times across selected models, and calculate your share of mentions or recommendations against the tracked competitor cohort. That creates an answer-based share of voice rather than a ranking-based one.
Which AI Visibility Tracking Success Metrics Matter Most?
The most useful starting metrics are Brand Mention Rate, Recommendation Rate, Prompt Coverage, Share Of Voice In AI Answers, Model-Specific Visibility, and Visibility Volatility. Together, they show whether the brand appears, whether it is favored, how broad that visibility is, and how stable the result is.
What Is The Difference Between Mention Rate And Recommendation Rate?
Mention Rate measures whether the brand appears at all in an answer. Recommendation Rate is narrower and stronger because it measures whether the answer positively recommends the brand as a solution, provider, or best-fit option.
How Often Should AI Visibility Metrics Be Measured?
A monthly baseline is usually the right default because it balances strategic signal with operational noise. Weekly measurement is useful during launches, messaging changes, competitive shifts, or major model updates.
What Makes The Most Accurate AI Visibility Metrics Software?
The most accurate tools use repeated sampling, clear mention-versus-recommendation rules, prompt versioning, model-aware normalization, and audit logs. Accuracy comes from representing variability honestly, not from pretending the system behaves like a static ranking engine.
How Can Startups Improve AI Visibility Quickly And Sustainably?
Startups usually improve fastest when they focus on high-intent prompts, publish canonical problem-solving content, tighten category positioning, and earn citations from neutral, trusted websites. That combination improves both retrieval and recommendation potential over time.
How Do You Create AI Visibility Metrics Benchmarks For Industries?
Good benchmarks use anonymized cohorts, fixed prompt sets, model-specific reporting, and segmentation by journey stage or prompt category. Quarterly updates are typically enough to keep the benchmark relevant as models and interfaces change.
How Do You Compare Visibility Across ChatGPT, Gemini, And Other Models?
The comparison should use the same prompt library, the same classification rules, and repeated runs for each model. Results should then be reported separately before any aggregation, because model behavior, answer structure, and citation logic differ.
What Is Visibility Volatility And Why Does It Matter?
Visibility volatility measures how much the result changes across repeated runs of the same prompt. It matters because unstable visibility is harder to trust and less useful for forecasting, even if a brand appears in some runs.
At first, we weren’t even thinking about AI visibility. We were focused on rankings and traffic like everyone else. But once we started testing our brand in ChatGPT and other AI tools, we realized we were barely showing up — even for topics we ‘ranked’ for. Gryffin gave us a clear picture of where we stood, how competitors were being cited instead, and what that actually meant for our pipeline. It shifted how we think about search entirely.








.png)
.svg)
.svg)
.svg)



