AI SEO: How Should You Define and Report Good Prompt Coverage?
Marcela De Vivo
Marcela De Vivo
April 23, 2026
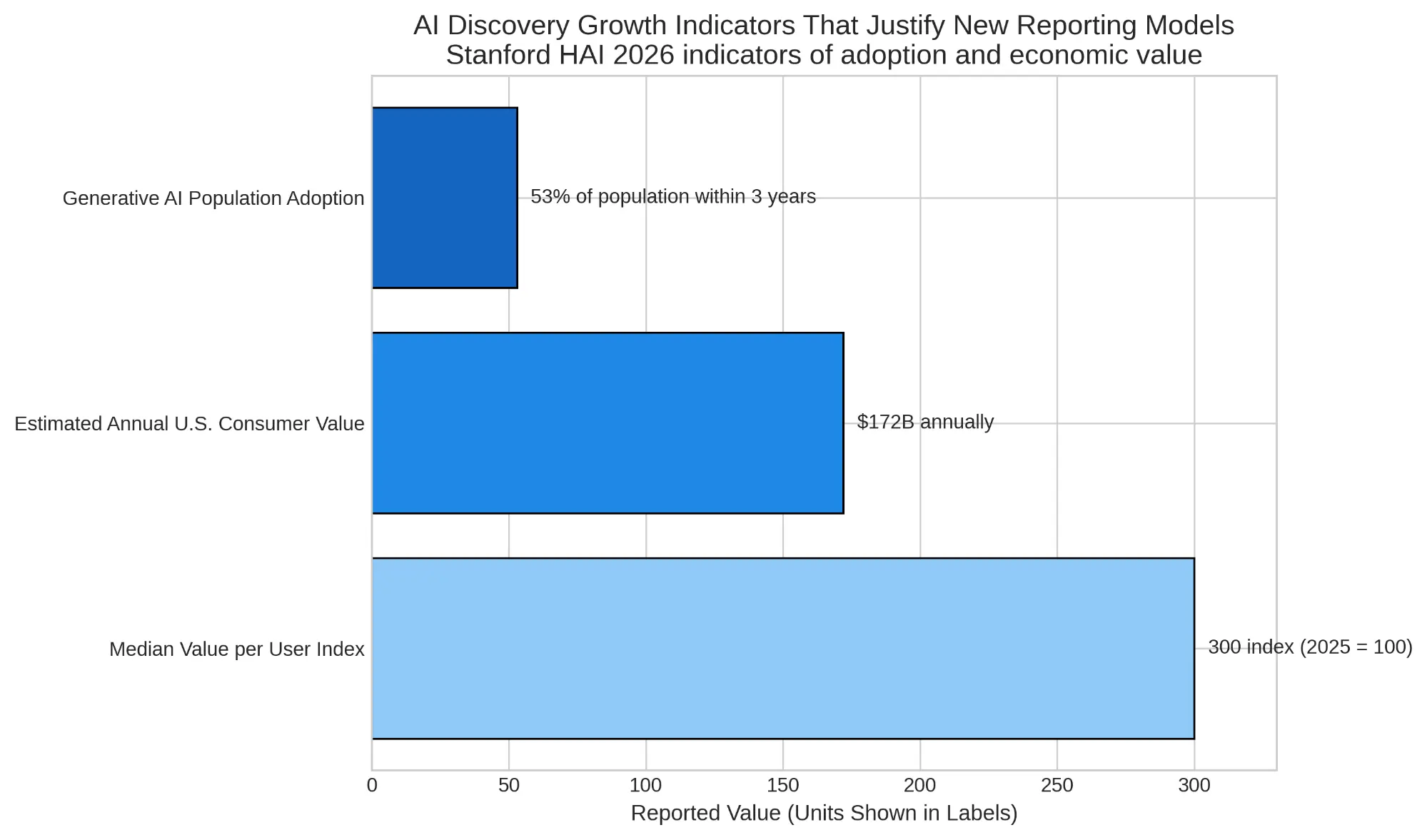
AI SEO is no longer just a theory about future search behavior. It is becoming an operating discipline for teams that need to understand how brands appear inside AI-generated answers, not merely how pages rank in a list of links. As generative AI adoption has accelerated, the measurement problem has become more urgent. Stanford HAI reports that generative AI reached 53% population adoption within three years, and estimated annual U.S. consumer value from generative AI tools reached $172 billion by early 2026.2 Those figures matter because they indicate that AI-mediated discovery is no longer niche. It is becoming part of how audiences research products, compare vendors, validate expertise, and form first impressions.
At the same time, traditional SEO dashboards do not fully capture what happens inside AI experiences. A page can have strong rankings and still fail to appear in an AI answer. Conversely, a brand can gain meaningful exposure in AI-generated responses even when classic organic visibility is uneven. Google itself has emphasized that AI search users tend to ask longer, more specific questions and often continue with follow-up prompts, which means measurement must account for question variation, conversational context, and attribution quality rather than position alone.1
That shift raises a practical question: what does good prompt coverage actually mean, and how should it be reported? The answer starts with a disciplined definition, a scoped prompt set, and a reporting model that distinguishes between simple presence and useful presence.
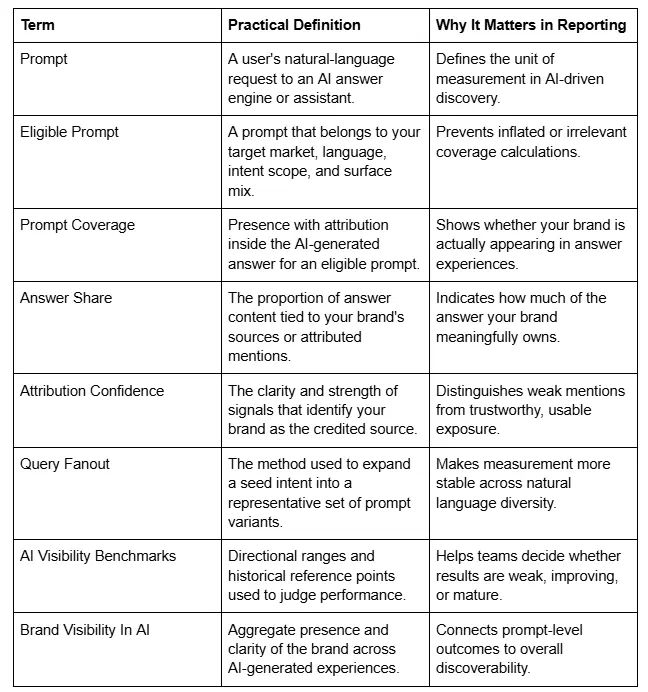
Before going deeper, it helps to align on terms. The table below provides a compact glossary that can be reused in reporting decks, dashboards, and stakeholder training materials.
What Is Prompt Coverage In AI SEO?
When marketers talk about prompt coverage in AI SEO, they are talking about the share of relevant prompts for which a brand earns an attributable presence inside an AI-generated answer. That presence can take several forms, including a cited link, a named mention of the brand, a product mention, an image or card, or a structured snippet that clearly points back to the brand's content. The important distinction is that AI SEO shifts the measurement frame from ranking position to presence plus attribution. In other words, the core question is not simply whether a page could be found, but whether the brand was included in the answering layer that users increasingly encounter first.
This matters because answer engines collapse multiple web sources into a single response. If your reporting model only tracks rankings and sessions, it misses the surface where much of the discovery now occurs. A strong AI SEO framework therefore begins by defining what counts as a prompt, what qualifies as an eligible prompt, and what kinds of presence are considered attributable.
Understanding Prompt Coverage
Prompt coverage is the formal percentage of a scoped prompt set where your brand appears with attribution in the AI-generated answer. The basic formula is straightforward: covered prompts divided by total eligible prompts. In practice, however, useful reporting adds context. Many teams calculate both an unweighted and a weighted version so they can distinguish broad visibility from commercial visibility. The unweighted metric answers, “How often are we present?” The weighted metric answers, “How often are we present where it matters most?”
The most practical formula for unweighted reporting is: Prompt Coverage = Covered Prompts / Eligible Prompts. The weighted version is: Weighted Prompt Coverage = Sum of (Prompt Weight × Covered Flag) / Sum of Prompt Weights. The weight may reflect commercial value, deal size, conversion likelihood, seasonality, strategic market priority, or estimated traffic potential. This matters because a one-point gain on a high-intent product comparison cluster may be more valuable than a ten-point gain on low-stakes awareness prompts.
What counts as “covered” should be documented in advance. A conservative methodology may require a resolved citation or exact-match brand mention, while a broader one may also count product names, image cards, and clear entity mentions. Without that standard, coverage percentages are not decision-ready.
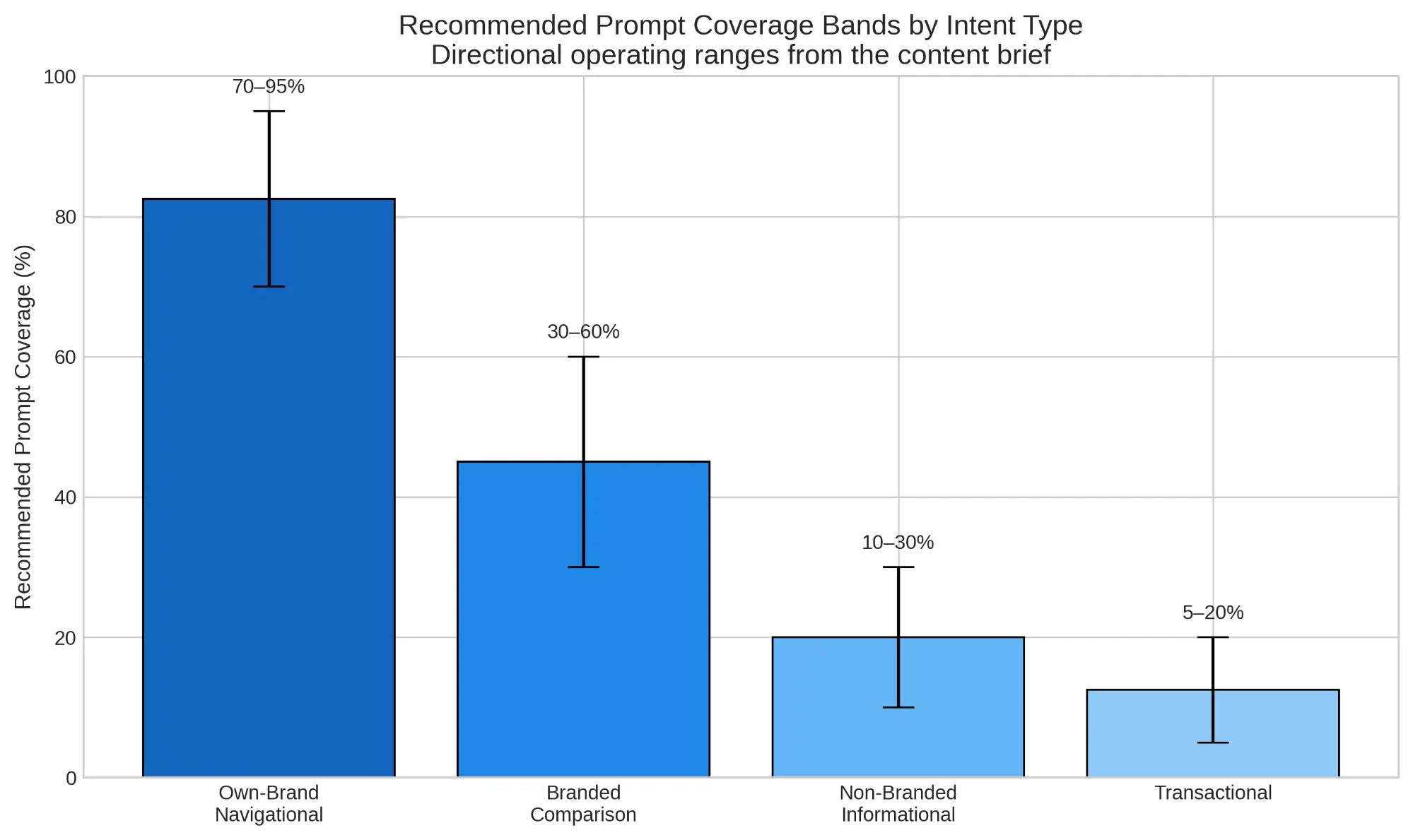
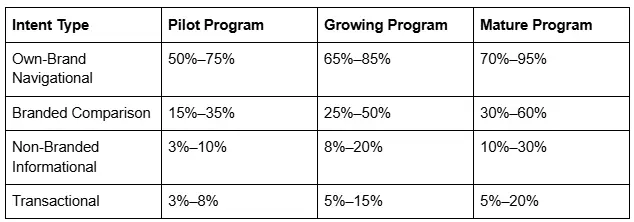
Good prompt coverage also depends on intent type. For own-brand navigational intents, where users are effectively looking for your company, products, or official resources, a mature program should expect very high coverage. For branded comparison intents, outcomes are usually more constrained because answer engines balance multiple entities and often avoid overtly promotional framing. Non-branded informational intents are harder still, because the brand is competing for inclusion in educational or problem-solving answers where the user may not know the company yet. Finally, transactional intents often depend heavily on structured data completeness, product feed quality, and verified business information rather than prose alone.14
The chart below summarizes the directional target bands from the brief, which are best understood as operating ranges rather than universal guarantees.
These bands reset stakeholder expectations. The achievable ceiling varies by intent, answer format, and platform policy, so mature teams report coverage in bands, segment by surface, and use confidence intervals when sample sizes are small.
What are AI Visibility Benchmarks?
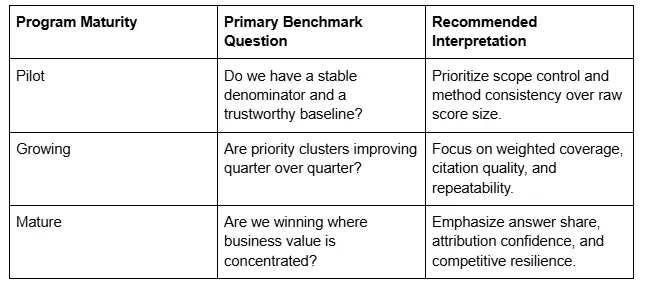
Ai visibility benchmarks are the reference points that help teams decide whether prompt coverage, answer share, and attribution quality are improving, stagnating, or underperforming. In practical reporting, benchmarks should be both cross-sectional and longitudinal. Cross-sectional benchmarks compare surfaces, markets, or peer sets at one moment in time. Longitudinal benchmarks compare current performance to the brand's own historical baseline over time. The second type is often more useful in the early stages of an AI SEO program because sector-wide benchmark datasets are still immature and surface behavior changes quickly.
The best benchmark systems track more than one variable. Prompt coverage is usually the lead metric, but it becomes more actionable when paired with answer share, attribution confidence, mention depth, and quality pass rate. A practical model treats pilot programs as baseline-building exercises, growing programs as lift-focused, and mature programs as quality- and resilience-focused.
Stanford HAI's 2026 report shows that generative AI adoption has already reached mass scale, which helps explain why even modest visibility gains can matter on high-value prompts.2
What is a Query Fanout?
Query fanout is the systematic process of expanding seed intents into many prompt variants so that prompt coverage is measured against natural language reality rather than a narrow keyword list. If teams measure only a handful of manually chosen prompts, their reporting becomes fragile. A slight shift in phrasing can produce a very different answer. Query fanout improves reliability by testing the same underlying intent through multiple semantically related prompts, then de-duplicating and scoring them in a disciplined way.
The reason query fanout matters is simple: users do not ask AI systems in one canonical format. A robust method starts with seed intents, expands them through paraphrase and modifier logic, then de-duplicates, screens for eligibility, and weights the final set by business relevance. The target is not maximum volume, but a stable, representative sample that does not swing wildly when phrasing changes.
The measurement pipeline diagram below shows where query fanout fits in the broader reporting system.
Because AI SEO depends on dynamic interfaces, query fanout should be paired with snapshotting, retries, and annotation. A stable testing cadence helps normalize volatility caused by temporary UI changes or model updates. Without that discipline, teams can misread surface instability as strategy impact. Query fanout is therefore not just a research technique. It is the foundation that makes prompt coverage reporting credible.
How do you Check Brand Visibility in AI?
Brand visibility in ai is the broader outcome that prompt coverage feeds into. It refers to how often, how clearly, and how favorably a brand appears across AI-generated experiences, including assistants, answer boxes, search overviews, chat interfaces, and multimodal results. Prompt coverage tells you whether you appeared on a specific scoped set of prompts. Brand visibility in ai tells you whether the market is actually encountering your entity in the broader AI discovery layer.
That distinction matters because a brand can have respectable coverage in a narrow test set while still underperforming in overall discoverability. Strong brand visibility in ai therefore depends on prompt coverage, answer share, attribution confidence, mention depth, and sentiment rather than presence alone.
Entity clarity is one of the most underrated drivers of visibility. Google states that structured data helps its systems understand page meaning and entities, and that markup should match visible content.4 In practice, that means teams should use consistent brand and product naming, maintain canonical pages for important claims, and connect entity references across editorial, product, and support content. The goal is not to “game” AI systems but to reduce ambiguity so attribution is easier and more reliable.
Google's AI-search guidance also recommends supporting textual content with high-quality images and videos for multimodal experiences.1 A useful reporting lens is to separate presence, clarity, and trustworthiness, especially because LLM outputs can still be unreliable.3
Which Measurement Framework And KPIs Should AI SEO Teams Use?
A good AI SEO reporting framework begins with scope definition. Teams should document the surfaces being measured, the target markets and languages, device types if relevant, the priority intent clusters, and the logic for eligibility. That scope becomes the denominator discipline that keeps reports trustworthy. Once scope is defined, the next steps are prompt creation through query fanout, prompt testing on a schedule, answer capture, attribution parsing, scoring, weighting, and quality review.
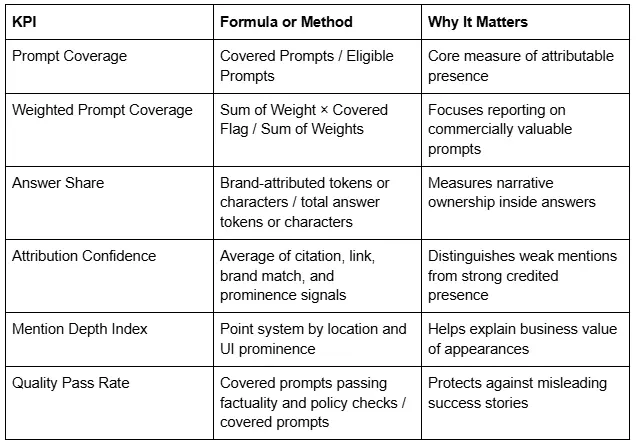
The KPI set should be compact enough for executive reporting but rich enough for operational analysis. Prompt Coverage is the percentage of eligible prompts where the brand is present with attribution. Answer Share measures how much of the answer content is attributed to the brand's sources, typically using tokens or characters capped to avoid inflation within a single answer. Attribution Confidence is a graded measure of citation clarity, link resolution, exact brand matching, and prominence. Mention Depth translates UI placement into a usable score, such as above-the-fold mention, inline citation, footnote citation, or carousel tile. Win Rate vs. Peers compares prompt outcomes across the same scoped set. Quality Pass Rate evaluates whether covered prompts pass factuality, freshness, and policy checks.
Sampling design deserves as much attention as scoring. Weekly or biweekly testing is usually appropriate for volatile surfaces, while monthly executive summaries are more digestible for leadership. Stratification by intent cluster, device, market, and language improves interpretability, and a stable control set protects trend integrity. Good AI SEO reporting should also explain why metrics moved by tying changes to content, technical, or distribution actions.
What Does Good Prompt Coverage Look Like By Intent And Maturity?
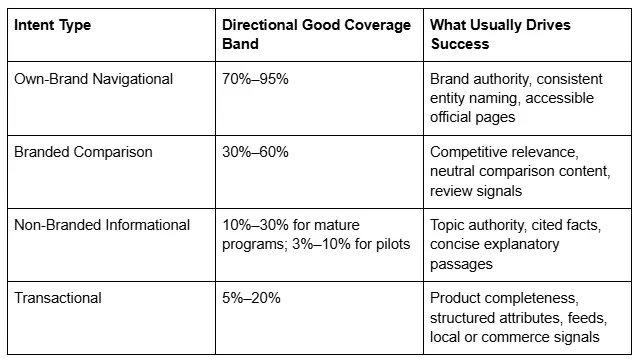
Good prompt coverage should be reported as a range rather than a single universal target because the ceiling varies by intent, surface, and program maturity. Own-brand navigational prompts should generally produce the strongest results because the answer engine has clear signals about brand identity and official sources. Branded comparison prompts are more contested. Non-branded informational prompts depend heavily on topic authority and concise factual coverage. Transactional prompts often require strong commerce or local data infrastructure in addition to editorial strength.
For pilot programs, success usually means achieving a stable baseline and moving one or two priority clusters. For mature programs, the standard rises: the brand should appear more often, more prominently, and in more commercially valuable answer contexts. That is why small numeric gains on high-value prompts can have outsized impact.
The benchmark ranges in the table below are useful for planning and expectation management.
These are directional operating ranges, not market law. Highly regulated industries, weak brand entities, multilingual complexity, or restrictive surface policies may lower achievable ceilings. The purpose of these bands is not to create false precision; it is to give teams a realistic framework for deciding whether they are underperforming, progressing, or leading within their own operating context.
How Should You Collect Data And Handle Sampling Volatility?
Data collection in AI SEO must assume that surfaces are dynamic and answers can vary by context. Teams should stratify sampling by intent cluster, market, and device context, then run the scoped set on a consistent cadence. Snapshotting is essential: store the prompt, timestamp, surface, answer text, visible citations, detected brand mentions, and a screenshot or structured record of the result. Retry rules, explicit eligibility logic, and a stable control set help prevent false negatives and false trend claims.
How Should You Report AI SEO Performance To Stakeholders And Executives?
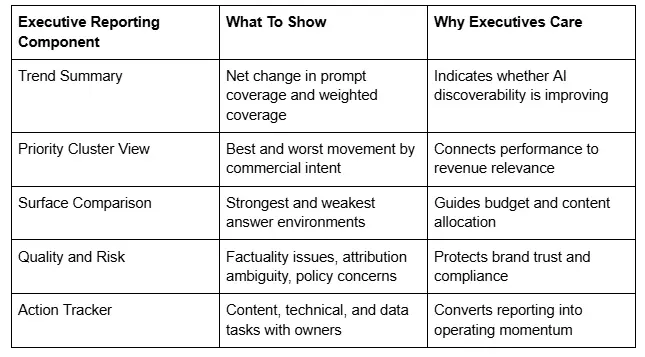
Stakeholder reporting should separate executive visibility from operational detail. The executive layer should answer three questions quickly: how much prompt coverage changed, where the most important wins and losses occurred, and what actions are expected next. The operational layer should explain cluster-level results, attribution quality, surface comparison, and remediation priorities. When both layers are present, AI SEO reporting becomes both decision-ready and execution-friendly.
A useful executive summary slide should show total prompt coverage trend, weighted coverage trend, answer share in priority clusters, top risks, and top actions with owners and dates.
A practical one-slide summary template can be phrased like this: “Coverage increased from 14% to 19% in the quarter, weighted coverage increased from 18% to 27%, the largest gains came from branded comparison content and product schema improvements, and the primary risk remains low attribution confidence on informational prompts in two markets.” That sentence structure keeps the narrative business-oriented and avoids burying the story in technical jargon.
How Can You Increase Prompt Coverage Without Creating Disjointed Content?
Improving prompt coverage starts with content completeness, but not in the shallow sense of simply adding more words. AI systems are more likely to cite pages that present concise facts, clear thresholds, well-structured explanations, and easily extractable answers. Google recommends unique, valuable content and notes that structured data helps provide machine-readable meaning.14 In practice, this means content should be written for users first, but organized so machines can accurately interpret entities, relationships, and claims.
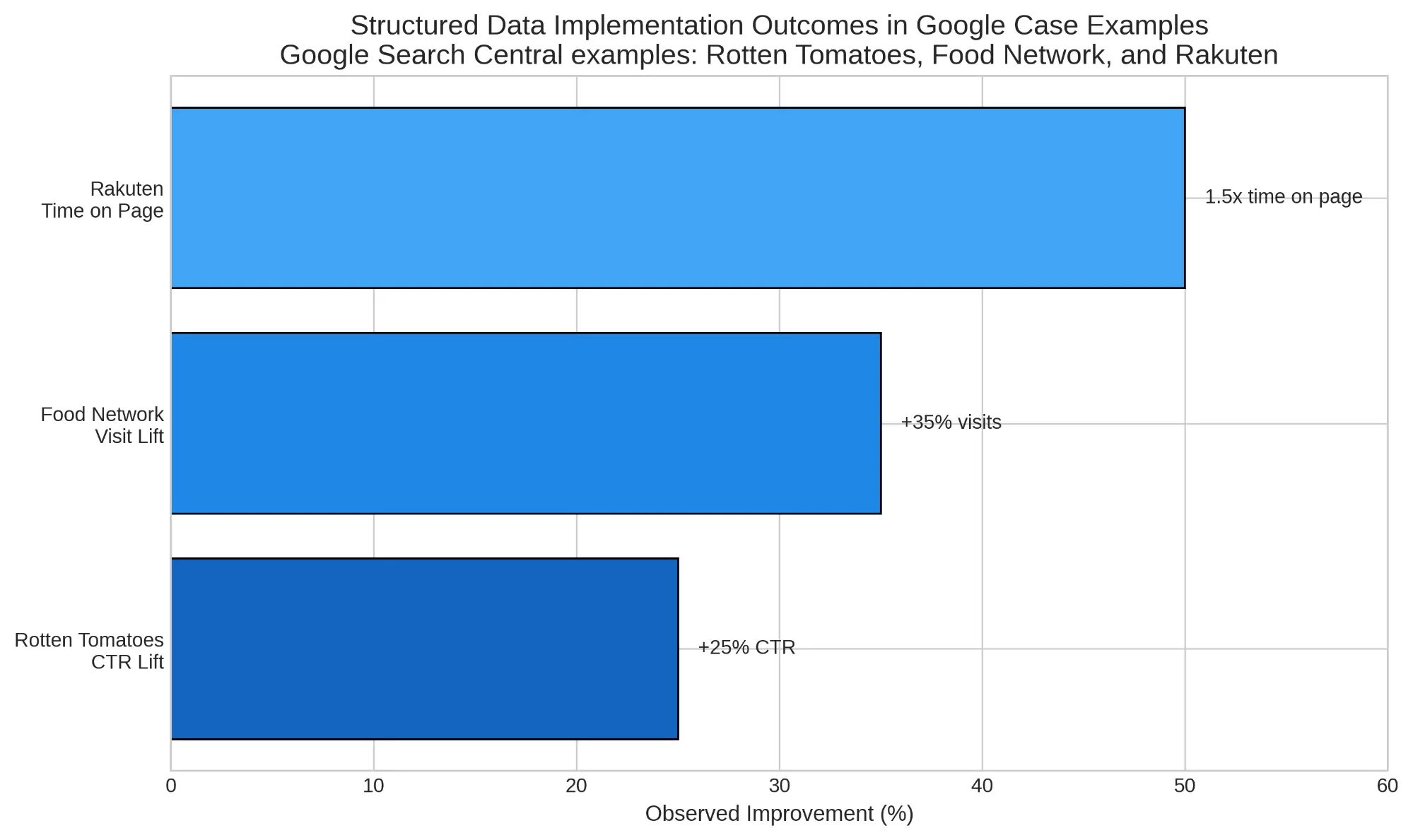
Structured markup is especially important for transactional and entity-sensitive experiences. Google's documentation emphasizes that structured data should match visible content and that accurate implementation matters more than exhaustive implementation.4 Case examples on Google's structured data documentation page report stronger engagement outcomes after markup adoption, including a 25% higher CTR for Rotten Tomatoes pages enhanced with structured data, a 35% increase in visits for Food Network after enabling search features across 80% of pages, and 1.5 times more time on page for Rakuten on pages implementing structured data.4 While those examples are not AI-specific guarantees, they reinforce the broader principle that machine-readable clarity improves how platforms interpret and present content.
Teams should also improve source clarity through clear bylines, expertise signals, recent update timestamps, canonical claim pages, and consistent naming conventions. The goal is not keyword stuffing; it is to answer major user questions clearly enough for people and machines to interpret the page without ambiguity.
What Common AI SEO Reporting Pitfalls Should Teams Avoid?
The most common mistake is measuring unnatural prompts that no real user would ask. That usually produces brittle gains and distorted dashboards. Query fanout should be grounded in real user intent, not internal jargon. A second mistake is overfitting to one surface interface. AI answers are dynamic, and a model or UI update can change result presentation overnight. Reporting should therefore diversify surfaces where appropriate and record the interface context in which each answer was observed.
A third error is ignoring attribution quality. Presence alone is not enough. A brand mention without a citation, a partial product reference, or a weak footnote placement should not be treated as equal to a prominent, resolved attribution. This is why attribution confidence and mention depth belong in the core KPI set. A fourth pitfall is confusing correlation with causation. Coverage may improve after a content launch, but unless the prompts, surfaces, and evidence trail are controlled carefully, teams cannot assume direct causality.
Risk governance also matters. Nature's research on LLM hallucinations underscores that generated answers can be unreliable and that uncertainty-aware controls are necessary.3 For AI SEO programs, that means maintaining factuality reviews for high-stakes content, documenting methodology limitations, respecting privacy constraints, and collecting data ethically. The goal is not only to maximize visibility, but to do so in a way that is defensible, compliant, and trustworthy.
How Is AI SEO Reporting Different From Traditional SEO Reporting?
Traditional SEO reporting is built around positions, impressions, clicks, and landing-page performance. AI SEO reporting is built around presence, attribution, answer share, and discoverability inside generated responses. In traditional SEO, one keyword often maps to one ranking snapshot. In AI SEO, one intent may require a full query fanout set, and visibility may shape brand recall before any click occurs. Google has noted that visits from AI Overviews can be higher quality, which supports measuring value rather than clicks alone.1 AI SEO should therefore extend traditional reporting, not replace it.
What Should Teams Do Next To Build A Strong AI SEO Reporting Program?
The clearest next step is to stop asking whether AI visibility should be measured and start defining how it will be measured consistently. A good prompt coverage program begins by finalizing intent clusters, building a representative query fanout, establishing a baseline across priority surfaces, and setting directional ai visibility benchmarks that match program maturity. Once that baseline exists, the team can prioritize the clusters with the highest commercial upside and design targeted content, technical, and data interventions.
The bigger idea is that AI SEO reporting should help organizations make better decisions, not merely generate a new category of vanity metrics. Prompt coverage becomes strategic when it connects visibility gaps to clear actions and executive understanding.
If you are building this program now, the most valuable call to action is straightforward: set your first coverage baseline, document your methodology, define quarterly ai visibility benchmarks, and tie every future change to specific content or technical actions. That is how AI SEO moves from buzzword to operating system.
FAQ: What is AI SEO
What Is AI SEO And How Is It Different From Traditional SEO?
AI SEO is the discipline of improving and measuring how a brand appears inside AI-generated answers, assistants, and answer engines. Traditional SEO focuses heavily on rankings, impressions, and clicks, while AI SEO focuses on prompt coverage, attribution, answer share, and the quality of visibility inside generated responses.
What Does Prompt Coverage Mean In AI-Driven Search?
Prompt coverage means the percentage of eligible prompts in a defined set where your brand appears with attribution in the AI-generated answer. It is the most practical baseline metric for understanding whether your content is being included in AI-driven discovery experiences.
How Do You Calculate Prompt Coverage For An Intent Cluster?
The simplest formula is covered prompts divided by eligible prompts. More advanced teams also calculate weighted prompt coverage so prompts with higher commercial value, stronger conversion likelihood, or greater strategic importance influence the result more heavily.
What Is Considered Good Prompt Coverage For Branded Vs Non-Branded Queries?
Good coverage depends on intent type. Own-brand navigational prompts may target 70% to 95% coverage in mature programs, while non-branded informational prompts may be strong at 10% to 30% because those prompts are more competitive and less directly associated with the brand.
How Often Should Prompt Coverage Be Measured And Reported?
Weekly or biweekly measurement is usually appropriate for volatile AI surfaces, while monthly and quarterly rollups work better for executive reporting. The key is to preserve a stable control set so trend lines remain trustworthy over time.
What Is Query Fanout And Why Does It Matter For Measurement?
Query fanout is the expansion of a seed intent into a representative set of natural-language prompt variants. It matters because AI answers can vary significantly by phrasing, and a narrow prompt list produces unstable reporting.
How Do You Measure Brand Visibility In AI-Generated Answers?
Brand visibility in AI-generated answers is measured through a combination of prompt coverage, answer share, attribution confidence, mention depth, and quality review. Looking at presence alone is not enough because weak or inaccurate mentions can misrepresent the brand.
What Are Common Errors When Reporting AI SEO Performance?
Common errors include measuring unnatural prompts, changing the prompt set too often, ignoring attribution quality, overfitting to one AI surface, and failing to document methodology. These mistakes make the numbers look more precise than they really are and reduce stakeholder trust.
At first, we weren’t even thinking about AI visibility. We were focused on rankings and traffic like everyone else. But once we started testing our brand in ChatGPT and other AI tools, we realized we were barely showing up — even for topics we ‘ranked’ for. Gryffin gave us a clear picture of where we stood, how competitors were being cited instead, and what that actually meant for our pipeline. It shifted how we think about search entirely.










.png)
.svg)
.svg)
.svg)



