How to Build an LLM Seeding Strategy That Gets Your Brand Mentioned
Marcela De Vivo
Marcela De Vivo
April 23, 2026
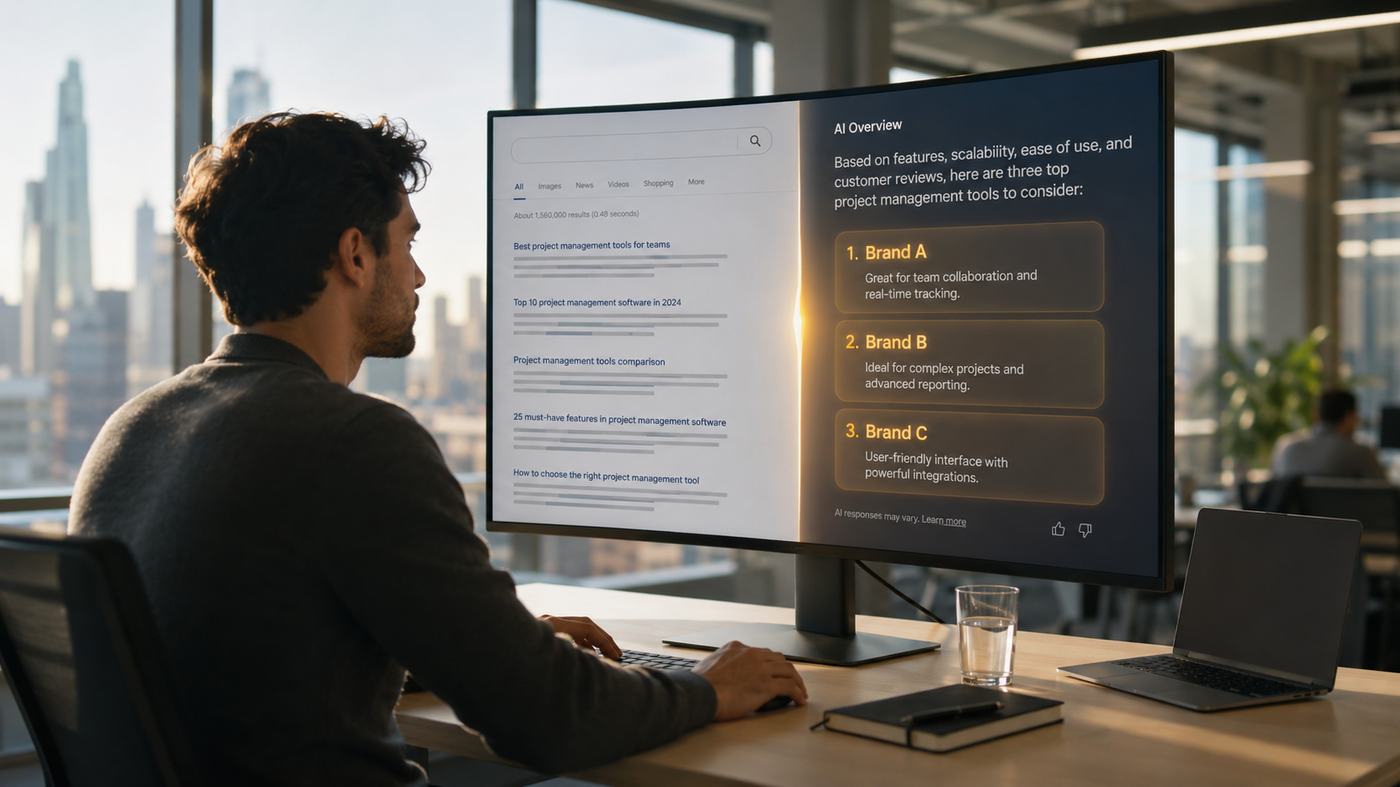
A growing share of product discovery no longer begins with a list of ten blue links. It begins with a prompt. A prospect opens ChatGPT, Perplexity, Gemini, Claude, or an AI layer inside search and asks a direct question: which platform is best, what tool should I use, what process works, which vendor is trusted, how do I compare options. The answer they receive is usually not a ranking page. It is a synthesized recommendation.
That change matters because it compresses the buyer journey. The user may never visit the pages that once introduced them to a brand. They may simply absorb the recommendation, remember two or three names, and continue their evaluation from there. In that environment, visibility is no longer defined only by rankings or sessions. Visibility is increasingly defined by whether an AI system knows your brand, understands your positioning, and sees enough evidence across the web to include you in its response.
This is where LLM seeding becomes useful. It gives brands a deliberate way to influence AI discovery without relying on old assumptions about search behavior. The goal is not to manipulate models or chase gimmicks. The goal is to publish highly usable information, distribute it across credible surfaces, and make it easier for AI systems to retrieve, summarize, and trust what your brand stands for.
For Gryffin AI, this is not just a content tactic. It is a new operating model for digital authority. The brands that adapt early will have an advantage in how they are framed, compared, and remembered. The rest will eventually discover that even strong websites can be invisible if they are absent from the places models use to construct answers.
What is LLM seeding, and why is it different from classic SEO?
LLM seeding is the practice of creating and distributing content in formats, contexts, and platforms that large language models are likely to retrieve, summarize, and cite when generating answers. The emphasis is not simply on ranking a webpage. It is on building enough structured, high-confidence evidence around a topic that AI systems repeatedly associate your brand with the right concepts, use cases, and recommendations.
Traditional SEO trained marketers to think in terms of rankings, clicks, keywords, and backlinks. LLM seeding does not replace those disciplines, but it changes what success looks like. Instead of asking whether a page sits in position three, the better question is whether your brand appears in an AI answer when a prospect asks a commercially relevant question. Instead of treating the click as the only meaningful event, LLM seeding treats a citation, recommendation, or favorable description as an upstream outcome that shapes future demand.
The distinction is subtle but important. Search engines mostly evaluate pages. AI systems often evaluate entities, relationships, and evidence. They synthesize across sources, compare wording patterns, and look for consistency. A brand that says one thing on its own site, something else in reviews, and nothing at all on third-party platforms creates ambiguity. A brand that appears consistently across explainers, comparisons, testimonials, interviews, and community discussions becomes easier to retrieve and easier to trust.
That is why LLM seeding works best when it is treated as a system rather than a one-off article campaign. It combines message architecture, content design, distribution strategy, and reputation signals into a single objective: make the brand easy for AI tools to understand and appropriate for them to mention.
A useful way to think about the shift is this: SEO often tries to win the page. LLM seeding tries to win the narrative. When someone asks a model for help, the brand that gets surfaced is not always the one with the most traffic. It is often the one with the clearest evidence package.
Why does LLM seeding matter now?
The rise of AI answers has created a discovery environment where many users get enough information without clicking through to the original source. That reduces the direct relationship between visibility and traffic. A company can become more influential in category conversations even while some traditional engagement signals flatten or decline.
For marketers, that can feel counterintuitive. For years, the web rewarded those who captured the click. Today, a brand may plant the idea earlier in the decision process and only receive the visit later, after the user has seen the name repeated in multiple AI responses or in follow-up searches. In practical terms, that means more of the buying journey happens before analytics platforms can measure it clearly.
The strategic advantage of LLM seeding is that it helps a brand stay present during that hidden phase. When a model presents your company next to established category leaders, it lends contextual authority. When the model describes your product using the exact positioning you want associated with it, it sharpens market understanding. When your brand is present across several prompt variations, it improves recall. Those effects compound over time.
The approach also narrows the gap between large incumbents and focused challengers. In classic search, dominance often flows to sites with stronger domain authority, larger link profiles, and entrenched rankings. In AI-generated responses, a newer or smaller company can still surface if its content is explicit, well-structured, and closely aligned with user intent. Models are looking for quotable, defensible answers, not merely the most visible homepage in a category.
LLM seeding matters now because the discovery layer has already changed. Waiting until traffic loss becomes severe is the wrong sequence. By that point, the model-facing conversation may already be dominated by competitors, review sites, and community voices that define your category without you.
How does an effective LLM seeding program actually work?
An effective program begins with a simple realization: models do not need more content from your brand; they need clearer evidence. That means the first task is not to publish randomly. It is to identify the prompts that matter, the claims you want associated with your brand, and the supporting proof you can publish across multiple surfaces.
Start by mapping the market questions that trigger discovery. These usually fall into a few familiar groups: broad educational queries, category comparisons, use-case questions, problem-solution prompts, objections, and brand-versus-brand evaluations. Once those are mapped, define the exact messages your brand should own within those conversations. If a company wants to be known as the best option for lean teams, the easiest platform to implement, the most reliable workflow assistant, or the strongest choice for regulated environments, those themes need to appear repeatedly and credibly.
The next step is to build what can be called a citation design system. This means packaging information in ways that are easy for both humans and models to extract. Strong AI-citable content tends to share several characteristics: it is explicit rather than vague, comparative rather than purely promotional, structured rather than sprawling, and supported by proof rather than assertions. Paragraphs should carry one idea at a time. Headings should reflect natural language questions or use cases. Key conclusions should be stated directly, not buried in metaphor or fluff.
After the content is created, distribution becomes the multiplier. Publishing on your own site is necessary, but it is rarely enough. Models learn from a mix of first-party, third-party, and community-based signals. That means your explanation on your own domain should be reinforced by a guest article, validated by customer reviews, echoed in a founder interview, referenced in a forum answer, and supported by documentation or examples where relevant. The power comes from repetition with variation.
Finally, the program has to be observed and refined. Manual prompt testing, brand mention tracking, branded search trends, direct traffic shifts, and sentiment monitoring all help reveal whether the market is beginning to echo your intended positioning. If the model mentions your brand but frames it as a budget tool when you want premium positioning, the program has not failed; it has surfaced a message alignment problem. That feedback is extremely valuable.
What should you publish if you want LLMs to cite your brand?
The strongest LLM seeding strategies do not rely on a single article type. They publish an ecosystem of complementary assets, each serving a different retrieval purpose. Some formats help a model answer broad category questions. Others support comparison prompts, practical implementation queries, or trust-oriented evaluations. The best portfolio gives AI systems multiple ways to encounter and describe the brand.
A useful starting point is the structured “best of” or recommendation guide. These work well because they mirror the way users ask AI systems for help. A person rarely types a query that only contains a product name. More often they ask for the best option for a team size, budget level, maturity stage, technical need, or workflow constraint. A good recommendation guide anticipates those distinctions. It explains selection criteria, states who each option is best for, and uses clear comparison language that can be quoted without heavy interpretation.
Hands-on reviews are another strong asset because they demonstrate first-hand evaluation. Whether the subject is a product, workflow, service, or framework, the presence of testing methodology adds credibility. The review becomes stronger when it states what was examined, who evaluated it, what conditions were used, and where the item performed well or poorly. AI systems tend to prefer material that reads like an informed assessment rather than a press release.
Comparison pages are especially valuable because they align directly with mid-funnel prompts. Many users ask models to compare one brand against another, or to choose between two categories of solutions. A useful comparison page does not merely list features. It explains tradeoffs, identifies which option fits which scenario, and provides concise verdicts that can be lifted into answers. If the copy says exactly who a product is for and why, the model has an easier time retrieving it.
FAQ content remains important because models are deeply shaped by question-and-answer patterns. The format is familiar, scannable, and efficient. The strongest FAQ pages begin with a direct answer, then add context, caveats, or examples. They are especially useful for handling objections, clarifying terminology, and addressing implementation steps that buyers often ask in conversational language.
Opinion-led articles also have a place in the mix, particularly for brands that want to own a point of view rather than simply summarize consensus. A strong opinion piece does not rely on provocation alone. It offers a clearly stated thesis, explains why conventional advice is incomplete, and gives readers a better framework to use instead. These pieces can travel well across newsletters, social threads, podcasts, and industry commentary, which expands the evidence base around the brand.
Visual explainers, frameworks, templates, and free tools are equally powerful when paired with enough surrounding context. A calculator, worksheet, template library, benchmarking rubric, or implementation checklist gives the market something usable. That usefulness often leads to mentions in forums, blog posts, newsletters, and AI summaries. The critical point is not the asset alone but the way it is introduced. Every resource should explain who it is for, what problem it solves, how to use it, and what outcome it supports.
Across all of these formats, structure matters as much as substance. Short sections, natural-language headers, summary boxes, tables, plainspoken verdicts, and explicit statements make content easier to retrieve and harder to misinterpret. The objective is not to oversimplify expertise. It is to package expertise in a way that can survive summarization.
How should the content be written so models can understand it?
Many brands assume they need a radically new writing style for AI visibility. In reality, they need a clearer editorial discipline. The best model-readable content is usually the same content a busy decision-maker appreciates: direct, organized, transparent, and specific.
First, every piece should have a clear retrieval purpose. The headline, introduction, and subheads should make obvious what question the page answers. If an article compares options, say that plainly. If it teaches a process, state the process. If it is a recommendation page for a particular audience, identify that audience early. Ambiguity weakens retrieval.
Second, each section should deliver one answer at a time. This is often called semantic chunking. Instead of burying five ideas in one sweeping section, break the page into discrete units that each carry a single claim, example, or decision point. A model can then extract the relevant part without dragging along unrelated material.
Third, make your reasoning visible. If you recommend a workflow, explain why. If you rate tools, show the criteria. If you endorse one path over another, describe the tradeoff. Explicit reasoning increases credibility and gives models more contextual clues about the basis for the conclusion.
Fourth, use balanced language. Strong content is not content that says everything is excellent. It is content that identifies strengths, limitations, and fit. Balanced phrasing is often more persuasive because it sounds like judgment rather than advertising. That distinction matters both to readers and to AI systems trying to infer trustworthiness.
Finally, maintain message consistency across the brand. If Gryffin AI wants to be known for a specific capability or use case, that language should appear not only on product pages but also in comparisons, interviews, customer stories, thought leadership, community answers, and review prompts. Repetition across contexts creates a stable entity profile.
Where should you seed the content for maximum pickup?
Publishing only on a brand-owned site limits the number of contexts in which a model can encounter your narrative. A stronger strategy distributes the same core themes across a range of surfaces that play different trust roles. Some channels establish authority. Others provide independent corroboration. Others supply practical examples and conversational language.
Third-party publishing platforms are useful because they often have clean formatting, strong crawlability, and a familiar editorial pattern. Articles placed on professional publishing platforms, newsletter ecosystems, or credible business networks can extend the reach of your perspective and expose it to different retrieval paths. The content should not be duplicate filler. It should adapt the main idea for the platform and audience while reinforcing the same positioning.
Industry publications remain highly valuable because they contribute external validation. A guest article, contributed quote, or expert commentary in a respected trade outlet can influence how a model interprets category authority. The key is to offer insight that stands on its own. Thin self-promotion rarely helps. Strong contributions usually explain a process, clarify a market shift, or provide a distinctive framework.
Community platforms are often where AI systems encounter natural, high-intent language. Forums, discussion sites, product communities, and niche groups contain questions phrased the way real users ask them. That makes these spaces especially important for seeding expertise. The right approach is not to invade communities with canned marketing lines. It is to answer well, provide specifics, and contribute in a way that would still be useful even if the brand name were removed.
Review ecosystems deserve special attention because they are rich with comparative and experiential language. Detailed customer reviews often contain the exact evidence models look for when deciding how to describe a product. This means brands should actively cultivate review quality, not just review quantity. Encourage customers to describe the problem they had, what alternatives they considered, what changed after adoption, and which feature mattered most.
Editorial-style resource hubs can also be effective when a brand needs more thematic breadth than a standard site architecture allows. A microsite, research center, or knowledge library can cover the wider industry conversation while still connecting back to the brand's core offer. Done well, this creates a more publication-like environment that signals depth rather than sales intent.
Social channels play a supporting role when used for educational substance. A short post may have limited retrieval value, but a well-developed thread, detailed caption, searchable video description, or transcript-backed explainer can become useful evidence. The lesson is not to be present everywhere. It is to publish the kinds of social assets that preserve context.
The most effective distribution programs do not depend on one viral placement. They accumulate evidence across layers. A model might first encounter a category framework in a guest article, then see the brand repeated in review language, then find the same use case clarified on a comparison page, then match it to a forum answer. That pattern of convergence is what turns a company into a credible recommendation.
How can Gryffin AI turn this into a repeatable operating system?
The simplest way to operationalize LLM seeding is to treat it as a repeating monthly cycle rather than an occasional experiment. Begin by identifying a cluster of prompts tied to one commercial theme, such as a core use case, a competitive motion, or a customer segment. Then create one primary first-party asset that answers the theme comprehensively. Around that asset, publish a small ring of reinforcing materials on other channels.
For example, a single topic cluster might include a how-to guide, a comparison page, an FAQ page, a founder perspective article, two community answers, a review prompt campaign, and a social thread that distills the main framework. Each piece would not repeat the same language word for word, but each would reinforce the same strategic message. That consistency matters more than volume.
This system also benefits from a formal message architecture. Decide in advance which three to five claims Gryffin AI wants models to associate with the brand. Those claims might relate to speed, implementation ease, intelligence quality, workflow fit, team type, or measurable outcomes. Once selected, they should guide briefs, interviews, customer proof collection, content structure, and review requests. A brand cannot control every mention, but it can dramatically increase the odds that the right descriptions recur.
Equally important is source diversification. If every supporting statement comes from the brand itself, the evidence remains thin. The goal should be to create a mix of brand-authored, customer-authored, expert-authored, and community-authored material. AI systems tend to place more confidence in narratives that appear independently corroborated.
How do you measure whether LLM seeding is working?
Measurement is the hardest part of the strategy because the path from mention to visit is often indirect. Yet the difficulty of measurement should not be confused with the absence of impact. The right approach is to combine several partial signals into a more complete picture.
The first signal is branded demand. If more people begin searching for your company name, product name, or leadership team after your presence in AI and third-party channels improves, that suggests market recall is strengthening. Direct traffic can also be informative, especially when it rises in parallel with branded queries. These are not perfect indicators, but together they often reflect growing awareness upstream of the click.
The second signal is manual prompt visibility. At regular intervals, run a controlled set of prompts across leading AI systems and document whether Gryffin AI appears, how often it appears, and how it is described. The wording matters. A mention framed as “good for small teams” communicates something different from a mention framed as “best for complex enterprise workflows.” Tracking those nuances helps the brand understand its emergent AI positioning.
The third signal is third-party mention growth. Unlinked references in articles, newsletters, podcasts, communities, and reviews are extremely valuable because they expand the web of evidence around the brand. Monitoring those mentions over time shows whether the narrative is spreading beyond owned channels.
The fourth signal is sentiment and attribute association. It is not enough to know that a model mentions the brand. You need to know what adjectives, comparisons, and claims consistently appear beside it. If positive attributes align with your intended positioning, the program is gaining coherence. If negative or irrelevant attributes dominate, the content strategy should adapt.
A practical measurement routine might involve monthly prompt testing, quarterly review audits, ongoing mention alerts, and a branded-demand dashboard. Over time, these signals become more useful in aggregate than any single metric on its own.
What does success look like over the long term?
Long-term success in LLM seeding does not mean appearing in every answer for every prompt. It means becoming a reliable part of the consideration set for the prompts that matter most to your business. Success looks like repeated inclusion, stable positioning, positive comparative framing, and growing brand recall across channels.
It also looks like strategic resilience. As AI interfaces continue to evolve, brands with a strong evidence footprint will adapt more easily because they are not dependent on one ranking position or one platform rule. They have built a broader layer of market understanding around themselves. Models can only summarize what they can find. The better the evidence package, the better the odds of being represented accurately.
For Gryffin AI, the opportunity is not simply to publish more content. It is to engineer discoverability in a world where answers are assembled, not merely indexed. That requires precision, repetition, distribution, and proof. Done well, the payoff is significant: more mindshare, stronger positioning, and a better chance of being the name buyers remember when they move from curiosity to action.
Final thoughts: build for citations, not just clicks
LLM seeding is best understood as the next layer of digital visibility. It does not eliminate the value of SEO, brand marketing, PR, customer advocacy, or product storytelling. Instead, it asks those functions to coordinate around a new question: when an AI system speaks on your category, does it know how to speak about you?
The answer will depend on whether your brand has created enough clear, structured, and distributed evidence to deserve inclusion. That means publishing pages that answer real prompts, creating comparisons that clarify fit, encouraging reviews that explain outcomes, contributing expertise where communities gather, and reinforcing the same core positioning wherever your brand appears.
The brands that win in this environment will not be the ones producing the most noise. They will be the ones producing the most coherent signal. If Gryffin AI wants to shape how the market discovers and evaluates it in an AI-first era, LLM seeding is not a fringe tactic. It is a practical, durable playbook for being cited, remembered, and trusted.
Frequently Asked Questions: How to Build an LLM Seeding Strategy
How is LLM seeding different from writing normal blog content?
Normal blog content is often written to attract traffic from search engines and convert a visitor after they click. LLM seeding is written to influence what AI systems retrieve, summarize, and recommend before the click ever happens. The difference is less about publishing volume and more about structuring content so it is explicit, comparable, and easy to cite.
Can a smaller brand really compete with larger companies in AI-generated answers?
Yes, provided the smaller brand publishes clearer evidence and more focused positioning around the prompts that matter. Large brands still benefit from awareness and authority, but AI systems frequently need specific, usable answers. A smaller company with better comparisons, stronger reviews, and tighter message consistency can become highly visible in those situations.
What is the most important content type to create first?
For most brands, the best starting point is a strong first-party guide paired with one comparison page and one FAQ page. That combination gives AI systems an educational asset, a decision-stage asset, and a prompt-friendly asset. From there, the next priority is to reinforce those ideas on third-party and community surfaces.
How long does it take to see results from LLM seeding?
The timeline varies by category, authority level, and content velocity. In practice, brands usually see the earliest signals in better prompt visibility, improved brand mention frequency, and stronger branded demand before they see a perfectly measurable conversion trend. The key is to treat the program as cumulative rather than expecting a single page to change outcomes overnight.
What should Gryffin AI measure first if it is starting from scratch?
The best initial dashboard includes branded search growth, direct traffic, manual prompt-test inclusion rates, third-party mention volume, and the most common descriptors attached to the brand. Those signals are enough to show whether the market is beginning to recognize and repeat the positioning Gryffin AI wants to own.
At first, we weren’t even thinking about AI visibility. We were focused on rankings and traffic like everyone else. But once we started testing our brand in ChatGPT and other AI tools, we realized we were barely showing up — even for topics we ‘ranked’ for. Gryffin gave us a clear picture of where we stood, how competitors were being cited instead, and what that actually meant for our pipeline. It shifted how we think about search entirely.















.png)
.svg)
.svg)
.svg)



