AI Search Tracker: A Practical Framework for Monitoring Visibility in AI Answers
Marcela De Vivo
Marcela De Vivo
June 4, 2026
25 min
The digital marketing landscape is undergoing its most profound transformation since the inception of the commercial web. Today, consumer discovery is shifting rapidly from clicking traditional blue links to consuming synthesized answers generated by artificial intelligence. According to a landmark study by McKinsey, nearly 50 percent of consumers now use AI-powered search engines, with a majority declaring it their primary source of insight when making purchasing decisions [1]. As a result, digital marketing professionals can no longer rely solely on legacy SEO metrics to measure brand health. To address this paradigm shift, organizations must adopt an AI search tracker - a dedicated, structured framework designed to monitor how a brand, product, or service is cited, mentioned, or ignored within AI-generated responses.
For years, search engine optimization (SEO) was a relatively straightforward, deterministic discipline. A brand targeted a keyword, earned a specific rank, and expected a predictable stream of traffic. In the modern era of Generative Engine Optimization (GEO), however, visibility is highly probabilistic and conversational. When a prospect inputs a complex prompt into ChatGPT, Gemini, or Claude, the model dynamically synthesizes an answer from a diverse range of web sources, citing only a select few. An AI search tracker provides the empirical data required to navigate this landscape, offering marketers a standardized methodology to measure, analyze, and optimize their brand's footprint inside AI-generated answers.
By establishing a robust AI search tracker, marketing teams can systematically identify which of their assets are earning citations, discover where competitors are capturing share of voice, and isolate the exact content patterns that trigger recommendations. This comprehensive guide outlines the operational framework, metrics, and workflows required to build a enterprise-grade tracking program, ensuring your brand remains visible in the age of generative discovery.
What Is an AI Search Tracker and Why Does It Matter for Modern Brands?
An AI search tracker is an analytical system designed to capture, record, and evaluate how a brand's products, services, and digital assets are represented within generative AI answer engines. Unlike traditional ranking software, which queries a static search index and records numerical positions, an AI search tracker interacts with probabilistic large language models (LLMs). It submits structured prompt sets, extracts the generated text, parses the embedded citations, and analyzes the sentiment and factual accuracy of the output.
The scope of an AI search tracker extends across two primary environments:
Standalone Conversational Interfaces: Independent AI platforms such as ChatGPT, Claude, and Perplexity, which users query directly for research, comparison, and decision-making.
Integrated Search Overviews: Search-engine-native features such as Google AI Overviews (AIO) and Microsoft Copilot, which overlay generative summaries directly onto traditional search engine results pages (SERPs).
By monitoring both environments, the tracker provides a unified view of a brand's generative search footprint, capturing the exact moments when a buyer is introduced to a brand or steered toward a competitor.
How does AI search tracking differ from traditional rank tracking?
Traditional rank tracking is built on the concept of keywords and positions. An SEO tool queries Google, finds a URL's position from 1 to 100, and reports a stable ranking. This model assumes that every user who searches for a specific keyword will see the exact same list of links.
AI search tracking, by contrast, operates in a highly dynamic, non-deterministic environment. Because LLMs generate responses on the fly based on probabilistic token prediction, the same prompt can yield different answers, citations, and formatting across different sessions, geographic locations, and user contexts. Furthermore, AI search is prompt-driven rather than keyword-driven; users input natural language queries, multi-step instructions, or comparative scenarios.
The following table contrasts the fundamental differences between these two measurement paradigms:
Where does AI search tracking fit in a modern digital marketing program?
AI search tracking is not a replacement for traditional SEO; rather, it is an essential extension of a modern organic search program. While traditional SEO continues to capture high-intent transactional clicks at the bottom of the funnel, Generative Engine Optimization (GEO) and Answer Engine Optimization (AEO) influence the research and consideration phases that occur much earlier in the buyer's journey.
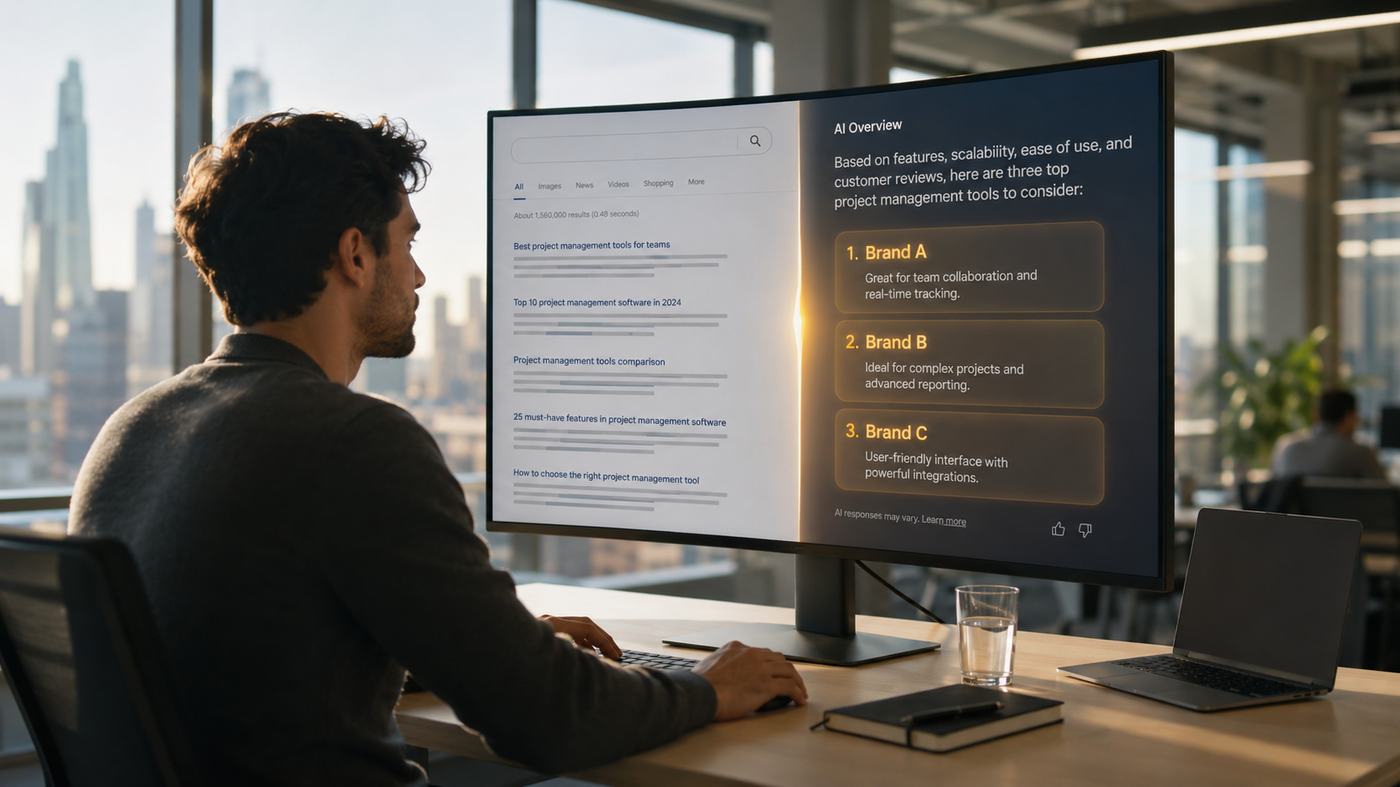
When a user asks an AI engine to compare solutions, draft a vendor shortlist, or troubleshoot a technical problem, the engine acts as an intermediary. It synthesizes information, makes recommendations, and shapes user perception before a click ever occurs. If your brand is not cited or recommended in these generative answers, you are effectively excluded from the consideration set. Integrating an AI search tracker into your marketing stack allows you to bridge this gap, aligning your SEO efforts with the way modern buyers actually discover information.
How Do Generative Search Engines Source, Synthesize, and Present Information?
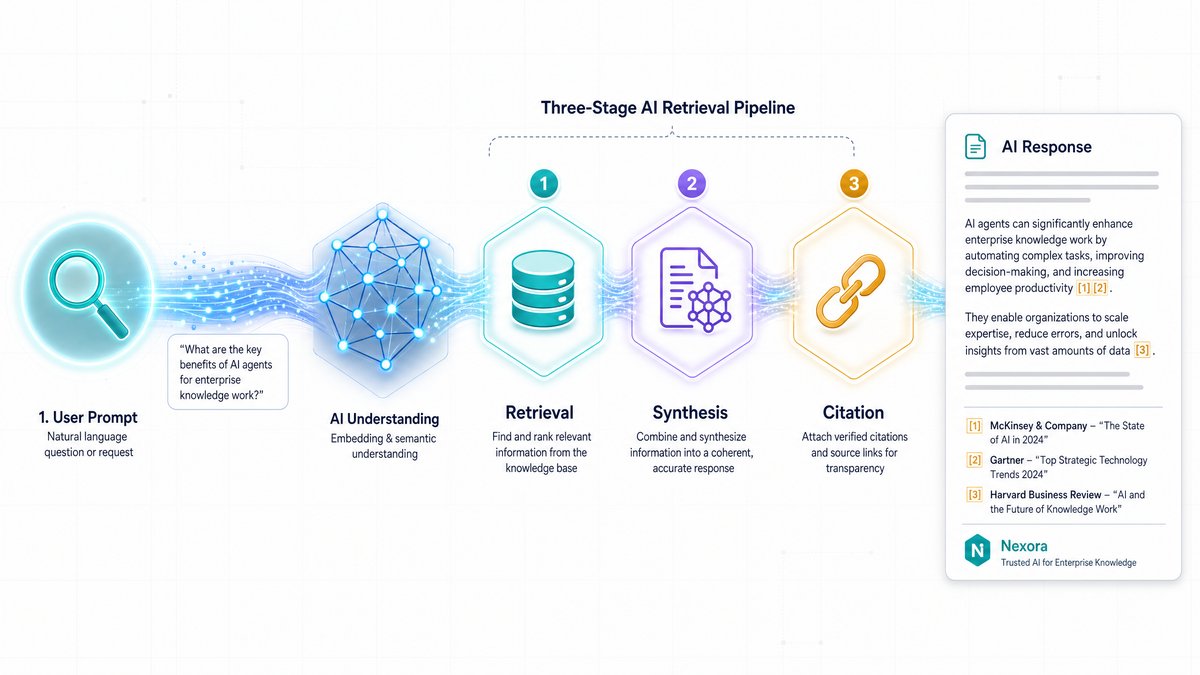
To track visibility effectively, marketers must understand how generative search engines construct their responses. Unlike standard LLMs, which rely solely on pre-trained static weights, modern AI search engines use a hybrid architecture known as Retrieval-Augmented Generation (RAG). This process involves three distinct phases:
Retrieval: When a user submits a prompt, the system translates the query into a vector representation and searches a live web index or database to find the most relevant, authoritative pages.
Synthesis: The system feeds the retrieved documents, along with the user's original prompt, into the LLM. The model processes the text, extracts key facts, and synthesizes a coherent, natural-language response.
Citation: As the model generates the text, it maps specific claims back to the source documents, embedding inline hyperlinks or footnotes.
Because the system relies on real-time web retrieval, a brand's visibility is heavily dependent on whether its content is accessible, crawlable, and structured in a way that the retrieval engine can easily parse.
Why do brand entities, topical authority, and source trust influence citations?
AI engines do not select sources at random; they prioritize entities and domains that demonstrate high trust and topical authority. In the context of RAG, an "entity" is a clearly defined, unique concept, such as a brand, product, or person. If an AI engine cannot easily identify and verify your brand as a distinct entity, it is highly unlikely to cite you.
Furthermore, AI models favor domains that exhibit deep topical authority. This means that a site with fifty comprehensive, highly structured articles on a specific niche is more likely to be cited than a generalist site with thousands of thin pages. To establish this level of authority, brands must focus on creating original, expert-backed content, utilizing advanced techniques such as AI schema markup to provide search engines with clear, machine-readable data about their organization and its expertise.
How do different prompt phrasings and user intents alter AI search outcomes?
Because AI engines are probabilistic, even minor changes in prompt phrasing can radically alter the retrieved sources and the final generated response. For example, a user asking "What is the best digital marketing platform?" might receive a highly generalized list of enterprise software suites. However, if the user refines the prompt to "What is the best digital marketing platform for small businesses looking to automate email workflows?" the engine will query a completely different set of niche blogs and product comparison pages.
This sensitivity to phrasing means that marketers must track a diverse array of prompts, mapping them to specific stages of the customer journey. To capture this complexity, teams must build a robust prompt taxonomy, ensuring they are monitoring informational, comparative, and transactional-adjacent queries.
What Key Signals, Prompts, and Citations Should an AI Search Tracker Monitor?
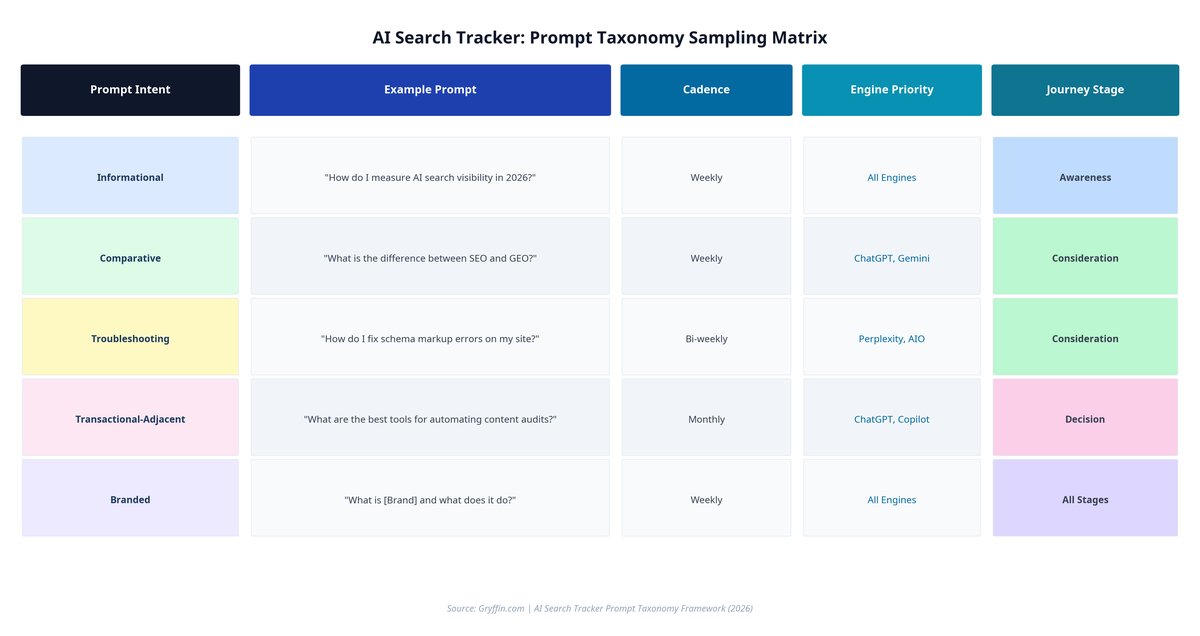
The foundation of any effective AI search tracker is its prompt library. Marketers should avoid tracking random queries; instead, they should build a structured taxonomy that reflects the actual conversational pathways of their target audience. A comprehensive prompt taxonomy should include the following categories:
Informational Prompts: Broad, educational queries focused on learning a concept (e.g., "How do I measure organic search visibility in 2026?").
Comparative Prompts: Mid-funnel queries where a user is evaluating multiple solutions or methodologies (e.g., "What is the difference between traditional SEO and GEO?").
Troubleshooting Prompts: Highly specific queries addressing a technical or operational problem (e.g., "How do I fix schema markup errors on my website?").
Transactional-Adjacent Prompts: Bottom-funnel queries where a user is seeking recommendations or preparing to make a purchase (e.g., "What are the top tools for automating content audits?").
To populate this taxonomy, teams can leverage their existing search data, using a specialized AI keyword research tool to identify conversational queries, question-based search terms, and semantic variations that are highly relevant to their target audience.
What are entity and brand mentions, and why are they critical?
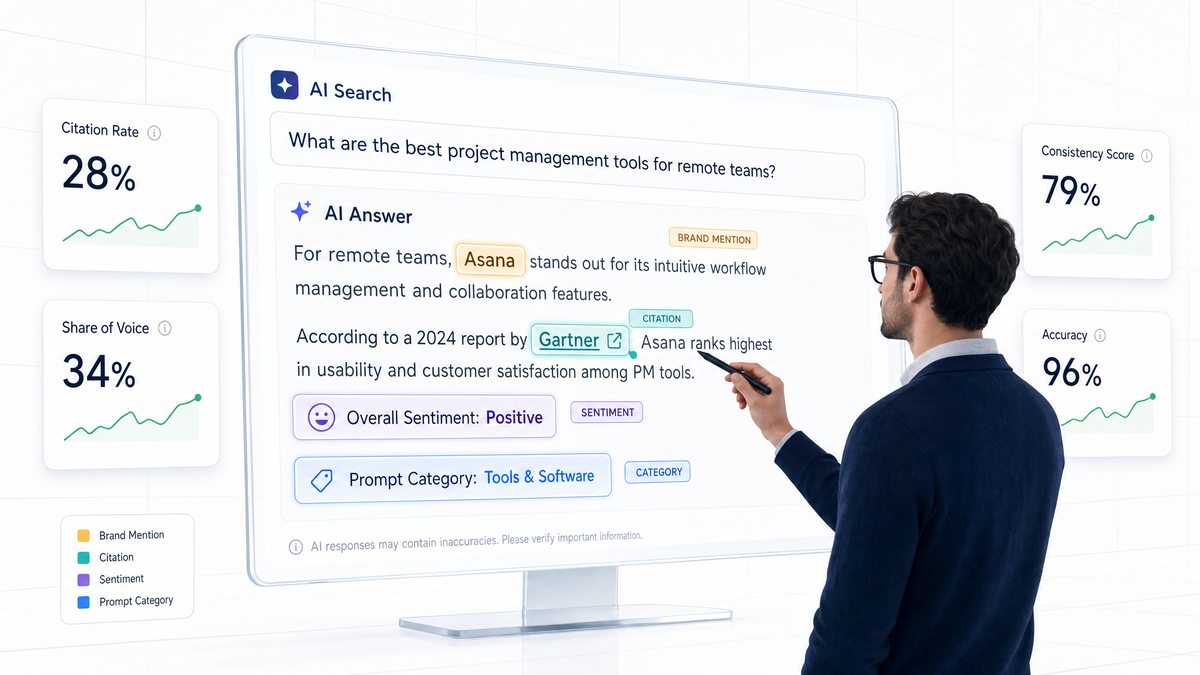
An AI search tracker must monitor two primary types of visibility: brand mentions and direct citations. A brand mention occurs when the AI engine references your company, product, or key personnel by name within the body of the generated text, even if it does not include a direct hyperlink to your website.
These mentions are critical because they indicate that the LLM recognizes your brand as a prominent entity within your industry. In many cases, a user will read an AI's recommendation and then perform a direct branded search on Google or visit the company's site directly. An AI search tracker must record these mentions, tracking exact matches as well as common spelling variations and product line names, to measure your overall brand prominence in the generative ecosystem.
How do you track citation signals, formatting, and prominence?
While brand mentions build awareness, direct citations drive traffic and conversions. A citation occurs when the AI engine embeds a hyperlink back to your domain, allowing users to click through and explore your content. When tracking citations, a basic "yes or no" is insufficient. A sophisticated AI search tracker should monitor several key citation signals:
Link Order and Position: Is your link placed at the very beginning of the response, or is it buried in a footnote at the bottom?
Snippet Location: Is your link tied directly to the main claim or recommendation, or is it relegated to a "related sources" sidebar?
Formatting Style: Does the engine display your full domain name, a clean anchor text, or a small, numbered icon?
Recurrence after Regeneration: If the prompt is submitted multiple times, does your citation remain consistent, or does it disappear during subsequent generations?
Tracking these details allows you to calculate a normalized prominence score, giving you a precise understanding of how effectively your content is being presented to the user.
Why are coverage, consistency, quality, and evidence capture essential?
Because AI engines are highly variable, tracking must be conducted over time and across multiple platforms to ensure data integrity. An AI search tracker must evaluate:
Coverage: The percentage of tracked prompts where your brand appears across different engines (e.g., appearing in Google AIO but being completely absent from ChatGPT).
Consistency: The frequency with which your brand appears across repeated generations of the same prompt, measuring the stability of your visibility.
Quality and Accuracy: The factual correctness of the information generated about your brand. Is the AI engine accurately describing your features, pricing, and use cases, or is it hallucinating outdated or incorrect details?
Evidence Capture: To troubleshoot drops in visibility or address brand safety concerns, the tracker must capture and store the raw response text, the unique prompt-response IDs, and screenshots of the generated output for future audit and reproducibility.
---
What Are the Best Methods to Collect AI Search Data Responsibly and Reproducibly?
When designing a data collection strategy, marketing teams often face a choice between manual sampling and programmatic tracking. Both approaches have distinct advantages and limitations, and a mature tracking program should integrate both:
Manual Sampling: This involves having a human analyst log into various AI interfaces, submit prompts, and record the results. Manual sampling is highly valuable for exploratory analysis, qualitative QA, and deep-dives into complex comparative prompts. It allows the analyst to observe the user experience firsthand, noting visual nuances, formatting styles, and subtle sentiment shifts that automated tools might miss. However, manual sampling is highly time-consuming, prone to human error, and virtually impossible to scale.
Programmatic Tracking: This approach utilizes automated scripts or API integrations to submit prompt sets at scale, parse the HTML or JSON responses, and record citation data in a structured database. Programmatic tracking is essential for establishing baseline metrics, monitoring broad prompt sets, and identifying long-term trends. It allows teams to track hundreds of prompts across multiple engines on a daily or weekly basis, providing the statistical significance required for executive reporting.
How do you manage rotation plans, geographic contexts, and personalization?
AI search engines are highly sensitive to user context. To ensure your data is representative, your collection methodology must account for several variables:
Geographic Rotation: AI search results, particularly Google AI Overviews, can vary significantly based on the user's IP address. A tracking program should utilize proxy networks to submit prompts from multiple geographic locations, ensuring visibility is monitored across all target regions.
Temporal Rotation: LLMs and search indexes are updated continuously. Submitting prompts at different times of the day and week helps identify temporary fluctuations versus permanent shifts in visibility.
Logged-in vs. Logged-out Contexts: Some AI engines personalize responses based on a user's past search history or account profile. Tracking should primarily be conducted in clean, logged-out, incognito environments to establish a neutral, unbiased baseline.
What governance, terms-of-use compliance, and secure storage practices are required?
Responsible data collection requires strict adherence to provider terms of service and legal standards. Many AI platforms have explicit policies regarding automated scraping or API usage. Marketers must ensure that their programmatic tracking methods utilize official APIs where available, or comply with established web scraping ethics, such as respecting robots.txt files and maintaining reasonable query rates to avoid overloading provider servers.
Furthermore, all captured data - including raw text, screenshots, and metadata - must be stored securely. Because AI responses can occasionally contain sensitive or proprietary information, organizations must implement robust data governance policies, ensuring that access to the tracking database is restricted to authorized personnel and complies with corporate privacy standards.
How do you ensure reproducibility with fixed prompt templates and change logs?
Because LLMs are non-deterministic, achieving 100 percent reproducibility is impossible. However, teams can minimize variability by implementing strict controls:
Fixed Prompt Templates: Ensure that prompts are submitted using exact, unvarying templates. Even a minor change, such as adding a period or changing a word from lowercase to uppercase, can alter the model's output.
Regeneration Counts: Submit each prompt multiple times (e.g., three to five times) during each tracking cycle and record the results of each run. This allows you to calculate an average visibility score, smoothing out the noise of individual probabilistic variations.
System Change Logs: Maintain a detailed log of all updates to your tracking system, including changes to prompt libraries, engine updates, and API modifications. This ensures that any sudden shifts in your metrics can be cross-referenced against system changes rather than actual drops in brand visibility.
What Metrics and KPIs Actually Matter for AI Search Tracking?
To turn raw data into actionable insights, organizations must establish a standardized, vendor-neutral KPI framework. The following metrics represent the core indicators of a brand's generative search health:
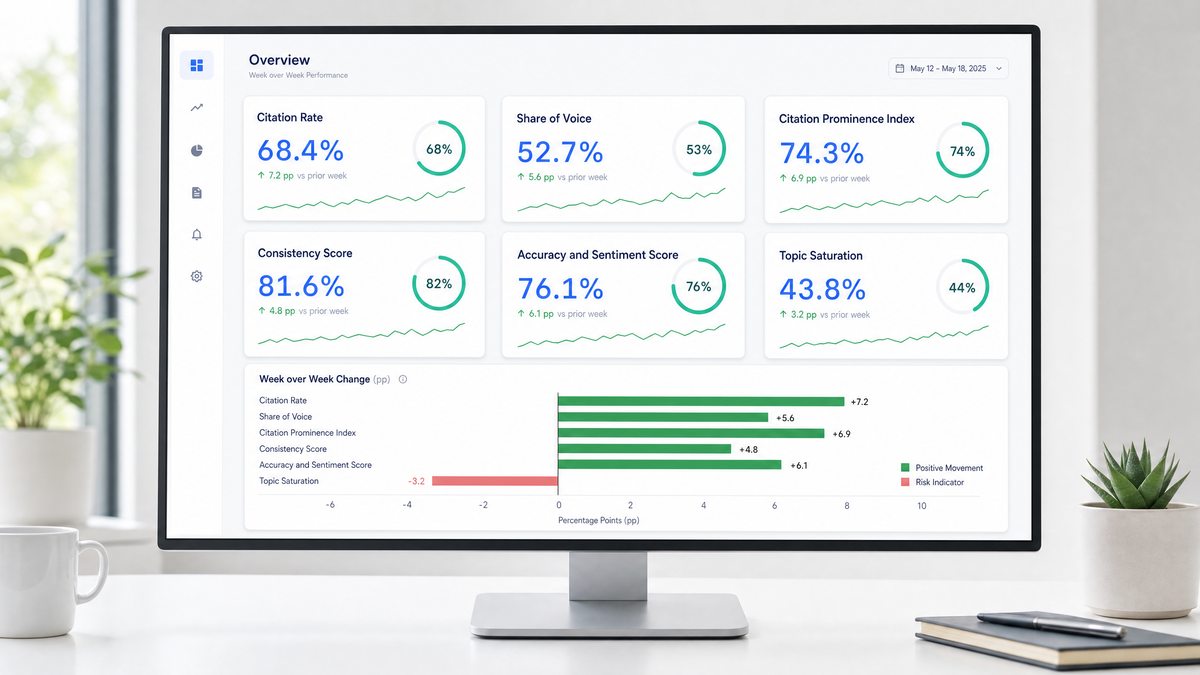
Citation Rate (CR)
The percentage of sampled prompts within a specific category that include at least one direct link to your domain. This is the most critical metric for measuring direct traffic potential.
For example, if you test a seed set of 100 prompts on ChatGPT and your website is cited in 25 of the generated responses, your Citation Rate is 25 percent.
Share of Voice (SoV)
The proportion of brand mentions your company receives compared to your direct competitors across all generated answers. This metric quantifies your competitive dominance in the conversational space.
If an AI engine recommends five different brands across a set of comparison queries and your brand is mentioned twice, your Share of Voice for those queries is 40 percent.
Citation Prominence Index (CPI)
A normalized score that evaluates the visual prominence and placement of your citations. Links placed in the primary introductory paragraph or within the main recommendation block receive a higher score than those relegated to footnotes or sidebar links.
Consistency Score (CS)
The frequency with which your brand or domain appears across repeated generations of the exact same prompt, measuring the stability of your visibility.
Accuracy and Sentiment Score (ASS)
The proportion of generated responses that reference your brand correctly and maintain a neutral or positive tone. This metric is essential for brand safety, helping identify instances where the AI engine hallucinates false features, outdated pricing, or negative comparisons.
Topic Saturation
The total number of subtopics, FAQs, or semantic clusters where your domain earns at least one citation. This metric measures the breadth of your topical authority.
Change Deltas
The week-over-week or month-over-month percentage movement for all of the above KPIs, allowing teams to track progress, detect sudden drops, and measure the impact of content updates.
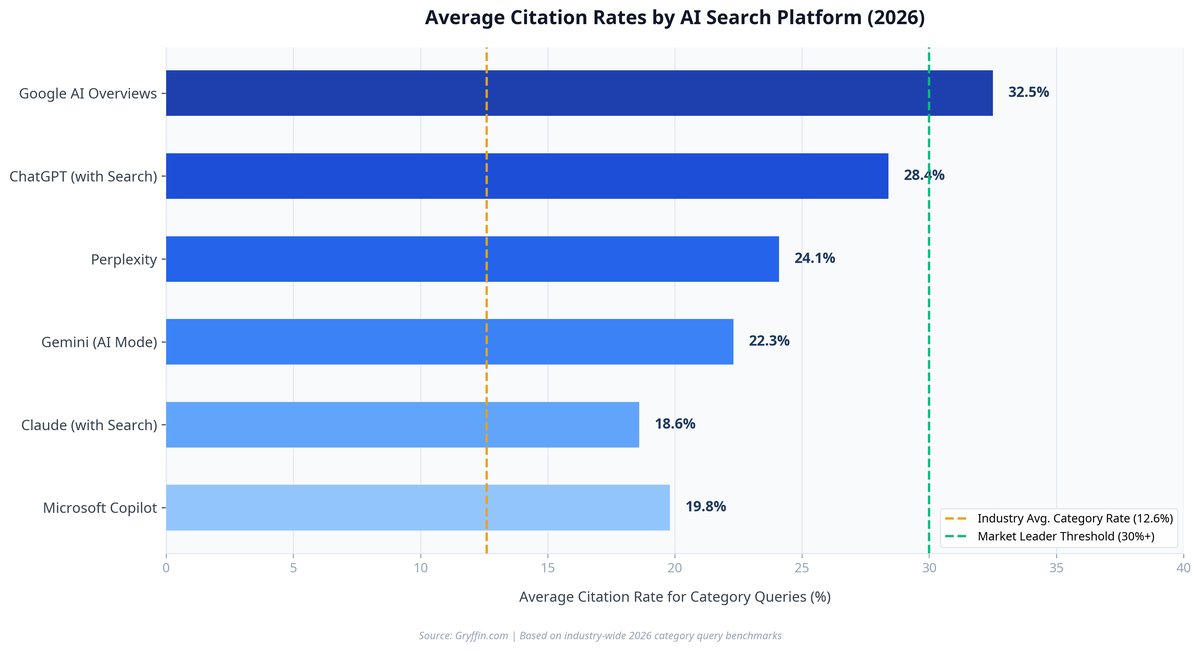
AI Citation Rate Benchmarks by Platform (2026 Data)
To help organizations benchmark their performance, the following chart illustrates the average citation rates for category-level queries across the major AI search platforms, based on industry-wide data collected in 2026:
As the data demonstrates, search-native platforms like Google AI Overviews and ChatGPT (with Search) exhibit the highest average citation rates, as their architectures are designed to blend generative synthesis with traditional web indexing. Conversational models like Claude, while highly sophisticated, tend to cite fewer sources, relying more heavily on synthesized, non-attributed summaries.
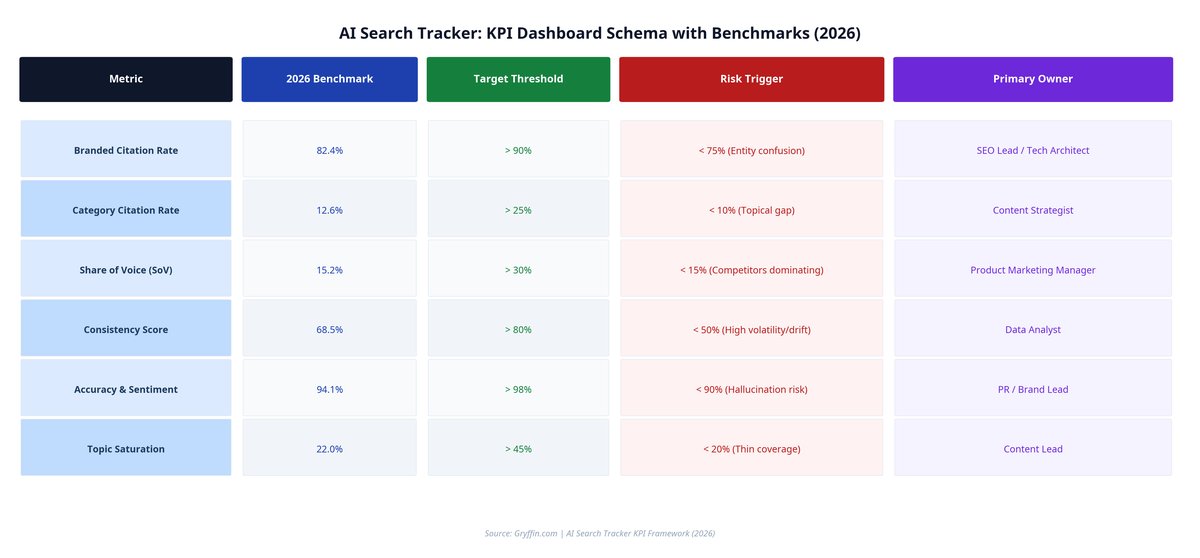
How to Build a Professional AI Search Tracking Dashboard
To present these metrics to stakeholders effectively, organizations should design a unified dashboard. The following schema outlines a professional dashboard layout, including target thresholds and action triggers:
By monitoring this dashboard weekly, marketing teams can quickly detect anomalies, trace them back to specific model updates or content changes, and deploy targeted optimization strategies.
What Key Factors Influence Whether Your Content Is Cited by AI Search Engines?
Earning citations in AI-generated answers is not a matter of luck; it is the direct result of aligning your digital assets with the specific retrieval and synthesis patterns of generative engines. The primary influencing factors can be divided into content-level, technical, and structural categories:
Content Quality and Credibility Signals
AI engines prioritize content that exhibits high levels of trust, originality, and first-hand expertise. To satisfy these retrieval algorithms, brands must focus on several key editorial practices:
Originality and Depth: Publish primary research, proprietary data, and unique case studies. AI models are trained to synthesize existing information, meaning they are highly attracted to unique, primary data points that cannot be found elsewhere.
Demonstrated Expertise: Ensure that all articles are written or reviewed by verified subject-matter experts. Include transparent author bios, links to professional profiles, and a clear revision history.
Source Trust: Cite authoritative, primary sources within your own content. Linking to academic research, government reports, and established industry standards signals to retrieval engines that your content is grounded in fact.
Editorial Rigor: Maintain strict quality standards. Avoid thin, repetitive, or overly promotional copy. AI engines favor objective, balanced writing that answers user questions directly and neutrally.
To ensure your content meets these high standards, marketing teams should establish a systematic process for AI for content audits, regularly reviewing their existing library to identify and enrich thin or outdated pages.
Technical Clarity and Crawlable Architecture
If an AI engine's retrieval crawler cannot easily access and parse your website, your content will never be cited, regardless of its quality. Technical optimization for GEO requires:
Crawlable Infrastructure: Ensure that your site is fully crawlable and does not block search engine bots or AI crawlers (such as GPTBot, ClaudeBot, or Google-Extended) in your robots.txt file, unless you have specific strategic reasons to do so.
Clean Canonicalization and Sitemaps: Maintain an XML sitemap and ensure that canonical tags are implemented correctly to prevent duplicate content issues.
Structured Data and Schema Markup: Implement comprehensive schema markup, including Organization, Product, Article, and FAQ schema. This provides search engines with explicit, machine-readable data about your entities, making it easier for AI models to verify and cite your brand. If you encounter errors, leverage specialized tools like an AI structured data error fixer to quickly resolve code discrepancies.
Consistent Entity Naming: Maintain strict consistency when referencing your brand, products, and key executives across your website, social profiles, and third-party directories. Discrepancies in naming conventions can confuse entity resolution algorithms, leading to omission from AI responses.
Retrieval-Friendly Writing Patterns
AI retrieval engines are designed to match user prompts with concise, direct answers. To make your content highly retrieval-friendly, authors should adopt specific writing patterns:
Concise Definitional Paragraphs: Begin informational sections with a clear, 40 to 60 word definition of the core topic. This structure is highly optimized for featured snippets and AI overview extraction.
Structured FAQ Sections: Include a dedicated FAQ section at the end of key articles, using the exact, conversational questions that users are likely to search for.
Clear Section Headers: Use descriptive, title-case subheadings (H2s and H3s) that resemble common search prompts.
Bullet Points and Tables: Organize complex data, comparisons, and step-by-step instructions into clean Markdown tables or bulleted lists. AI models frequently extract these structured blocks to populate comparison tables or lists in their generated answers.
To scale these practices across your organization, teams should provide writers with comprehensive training, or hire a specialized AI content writer who understands how to balance human readability with LLM optimization.
Building an AI Search Tracker Program: People, Process, and Workflows
Operationalizing an AI search tracker requires a cross-functional team with clearly defined roles:
SEO and GEO Lead: The strategic owner of the program. Responsible for defining the prompt taxonomy, establishing KPIs, analyzing trend data, and aligning optimization efforts with the broader marketing strategy.
Data and Analytics Analyst: The technical operator. Responsible for managing the programmatic tracking tools, configuring API integrations, maintaining the dashboard, and ensuring data accuracy and reproducibility.
Subject-Matter Reviewers: Industry experts who review generated responses for qualitative accuracy, ensuring that the AI engine is not misrepresenting complex technical features or compliance details.
Governance and Brand Lead: Responsible for monitoring brand safety, managing hallucination risks, and executing escalation procedures if the brand is associated with misinformation.
How do you build and maintain prompt libraries and entity dictionaries?
A tracking program is only as good as its inputs. Teams must build and continuously update two core resources:
The Prompt Library: A centralized repository of tracked prompts, organized by user intent, product line, and journey stage. This library should be refreshed quarterly to remove outdated queries and integrate emergent conversational trends.
The Entity Dictionary: A document that outlines the exact naming conventions, product descriptions, and key claims that the brand wants AI engines to associate with its entity. This dictionary serves as the baseline for measuring accuracy and sentiment.
What is the operational cadence and workflow?
To ensure consistent monitoring without overwhelming resources, teams should adopt a tiered operational cadence:
Weekly Light Checks: Run a core set of high-priority branded and transactional prompts to detect sudden drops in visibility or emergent brand safety risks.
Monthly Reporting: Execute the full prompt taxonomy across all major engines. Update the KPI dashboard, analyze competitive movement, and deliver a comprehensive performance report to marketing leadership.
Quarterly Deep-Dives: Conduct a thorough audit of the tracking program. Refresh the prompt library, review competitive share of voice, evaluate model drift, and adjust content and technical optimization strategies accordingly.
Risks, Edge Cases, and Governance in Generative Search Tracking
How do you manage model drift and system updates?
One of the greatest challenges in AI search tracking is model drift - the tendency of an AI model's behavior, accuracy, and citation patterns to change over time as the provider updates its weights, fine-tuning, or retrieval algorithms. A brand can experience a sudden, dramatic drop in citation rate not because of any change to its website, but because an engine updated its retrieval weights to favor a different class of domains.
To manage model drift, analysts must cross-reference any sudden shifts in metrics with known industry updates. Maintaining a detailed change log and utilizing a diverse prompt set helps smooth out the impact of individual model updates, ensuring that strategic decisions are based on long-term trends rather than temporary technical noise.
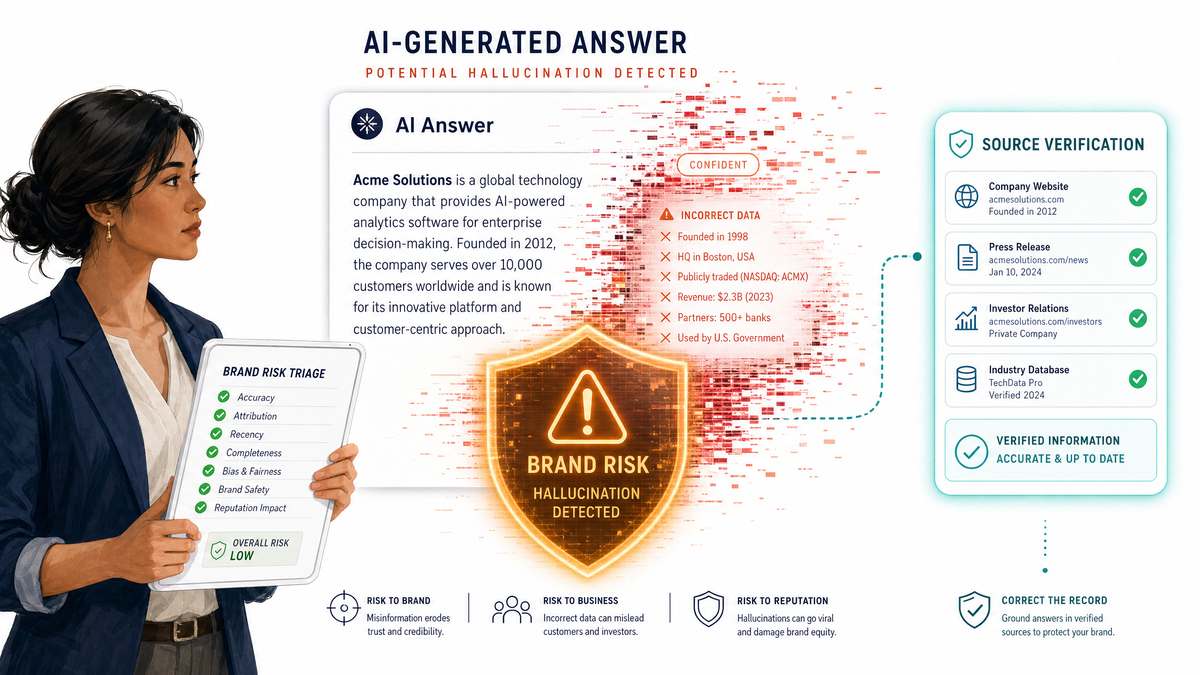
What is the triage logic for hallucinations and misattributions?
Because LLMs are probabilistic, they are prone to hallucinations - generating false, misleading, or completely fabricated information. For brands, this represents a significant risk. An AI engine might claim that your product lacks a key feature, list an incorrect pricing tier, or attribute a competitor's security breach to your company.
To mitigate this risk, organizations must establish a clear triage logic:
Detection: The AI search tracker flags a factually incorrect or negative brand mention.
Verification: A subject-matter reviewer evaluates the response to confirm the error and document the exact prompt-response ID and screenshot.
Root-Cause Analysis: Analyze the retrieved sources to determine why the AI hallucinated the error. Is there outdated information on a third-party review site? Is your own pricing page confusing or poorly structured?
Remediation: Deploy targeted content updates to resolve the underlying confusion. If the error is driven by a prominent third-party publisher, execute digital PR outreach to request a correction, ensuring that the AI's future retrieval cycles pull accurate data.
How do you handle compliance, privacy, and terms of use?
As generative search tracking matures, regulatory compliance and privacy must remain at the forefront. Organizations must ensure that all data collection practices comply with local privacy laws (such as GDPR and CCPA) and respect the intellectual property rights of content creators. Programmatic tracking must be conducted responsibly, avoiding any techniques that could be construed as unauthorized access or a violation of provider terms of use.
Conclusion: Emphasizing Editorial and Data Excellence
The rise of generative search represents a fundamental shift in how information is organized, synthesized, and discovered. In this new paradigm, traditional rank tracking is no longer sufficient to measure brand health. By building a comprehensive AI search tracker, organizations can transition from passive observers to active participants in the generative ecosystem.
Ultimately, winning in AI search is not about exploiting technical loopholes or "gaming" the algorithms. It is about committing to absolute editorial and data excellence. AI engines are designed to find and synthesize the most authoritative, trustworthy, and clear information available. By producing deep, original content, maintaining a flawless technical architecture, and systematically measuring your visibility with a dedicated tracker, you can ensure that your brand remains the trusted authority that AI engines recommend to your future customers.
Frequently Asked Questions (FAQs): AI Search Tracker
What is an AI search tracker?
An AI search tracker is an analytical framework and methodology used to monitor, record, and evaluate how a brand, product, or content appears within generative AI answer engines like ChatGPT, Claude, Perplexity, and Google AI Overviews. Unlike traditional SEO rank trackers that monitor static keyword positions, an AI search tracker evaluates probabilistic natural language prompts, measuring brand mentions, citation rates, and overall share of voice. To build a solid foundation, teams often begin by conducting a comprehensive AI competitor analysis for GEO to identify visibility gaps.
How is AI search tracking different from SEO rank tracking?
Traditional SEO rank tracking measures a website's position in a deterministic, ordered list of search results based on specific keywords. AI search tracking, by contrast, operates in a probabilistic environment where natural language prompts yield dynamic, synthesized textual answers. While SEO focuses on securing a high position on a search page, AI tracking focuses on earning direct citations and brand recommendations within the AI-generated text itself. To learn more about this transition, explore our complete Google AI Overviews ranking guide.
Which prompts should I include in a prompt library?
Your prompt library should feature a structured taxonomy of natural language queries that mirror your customers' actual research behaviors. This includes informational prompts (to build topical authority), comparative prompts (to evaluate different solutions), troubleshooting prompts (to resolve specific issues), and transactional-adjacent prompts (to secure product recommendations). Marketers can identify these conversational search terms by utilizing an advanced AI keyword research tool to uncover high-value, semantic queries.
How often should AI search visibility be measured?
To ensure accurate data without wasting resources, we recommend a tiered monitoring cadence. This includes weekly light checks on high-priority branded and transactional queries to detect sudden brand safety risks or drops in visibility, monthly comprehensive reports to update your core KPI dashboard, and quarterly deep-dives to audit your prompt library, evaluate competitive movement, and adjust your overall Generative Engine Optimization (GEO) strategy.
How do I document and reproduce AI responses reliably?
Because large language models are non-deterministic, you cannot achieve perfect reproducibility. However, you can establish a reliable baseline by using fixed, unvarying prompt templates, submitting each prompt multiple times (e.g., 3 to 5 times) per tracking cycle to calculate an average score, and maintaining a detailed system change log. Additionally, your tracker must capture and store the raw response text, unique prompt-response IDs, and visual screenshots to serve as verifiable evidence for future audits.
Which metrics indicate that my content is earning citations?
The primary metric is your Citation Rate, which measures the percentage of tested prompts that include a direct link back to your domain. You should also monitor your Share of Voice (SoV) to see how often you are mentioned compared to competitors, and your Citation Prominence Index, which evaluates the visual placement and order of your links within the generated text. To understand how content structure influences these metrics, read our guide on how to improve AI search visibility.
What should I do if an AI answer misrepresents my brand?
When an AI engine hallucinates incorrect details about your brand, you should follow a structured triage process. First, document the error with screenshots and prompt-response IDs. Second, analyze the retrieved sources to find where the misinformation originated (e.g., an outdated third-party review). Third, update your own website content to clarify the facts, and execute digital PR outreach to correct third-party errors. For a broader look at managing brand data, consult our guide on AI for content audits.
Does structured data help with AI citations?
Yes, structured data is highly influential. Implementing comprehensive schema markup (such as Organization, Product, and FAQ schema) provides retrieval engines with clean, machine-readable data about your brand and assets. This technical clarity makes it significantly easier for AI engines to identify, verify, and cite your website as an authoritative source. If you encounter technical implementation issues, you can utilize an AI structured data error fixer to resolve coding errors.
Can I attribute traffic influenced by AI answers?
Yes, but it requires a specialized approach. Unlike traditional search traffic, which passes clean referral data, traffic from AI engines is often categorized as direct or secure search. To attribute this traffic accurately, you should use UTM parameters on links within your controlled assets, monitor assisted conversions, and track changes in branded search volume. Understanding the mechanics of query fan-out in AI search can also help you map how conversational queries translate into actual site traffic.
How do I ensure compliance with provider policies?
To track responsibly, you must ensure that your programmatic collection methods align with each platform's terms of service. This means utilizing official developer APIs whenever they are available, respecting robots.txt guidelines, and maintaining conservative query rates to prevent server overload. Responsible data governance also requires storing all captured response data securely and restricting access to authorized team members.
At first, we weren’t even thinking about AI visibility. We were focused on rankings and traffic like everyone else. But once we started testing our brand in ChatGPT and other AI tools, we realized we were barely showing up — even for topics we ‘ranked’ for. Gryffin gave us a clear picture of where we stood, how competitors were being cited instead, and what that actually meant for our pipeline. It shifted how we think about search entirely.







.png)
.svg)
.svg)
.svg)



